In the fast-paced world of machine learning and data science, ensuring that your model performs well in real-world scenarios is absolutely crucial. Imagine developing a model that works beautifully on your test data, only to find out it flops when unleashed on the wild world of practical applications. That’s where the magic of validating models using cross-validation comes into play. Cross-validation is not just another buzzword in the data science toolkit—it’s an essential technique that provides a robust framework for assessing the predictive performance of your models. But hey, don’t just take our word for it. Dive into the data-driven world we inhabit!
For data scientists and analysts, keeping up with trends and tools that can enhance model reliability is the name of the game. Cross-validation is like a safety net, a guarantee that your model won’t fall flat when the stakes are high. This tool is not just a helpful add-on; it’s your personal quality assurance process before you ship your algorithmic masterpiece into production. Just as a dress rehearsal is crucial for a successful play, cross-validation ensures that your model is ready for the showtime, reducing the chances of overfitting and increasing the likelihood of outstanding real-world performance.
As we journey through this article, we’ll unravel the nuances and charms of validating models using cross-validation. Whether you’re new to this concept or a seasoned pro looking to refine your approach, buckle up for an insightful ride. Get ready to delve into the various techniques and uncover strategies that will elevate the accuracy of your predictions. Let the adventure of understanding cross-validation begin!
Why Cross-Validation is Crucial for Model Validation
As we delve deeper into the realm of machine-learning, one key realization emerges: models are only as good as their validation processes. Cross-validation offers a structure for ensuring that the story you tell with your data is both cogent and credible. You see, validation is practically an art form that must be mastered to genuinely understand the power and abilities of your model.
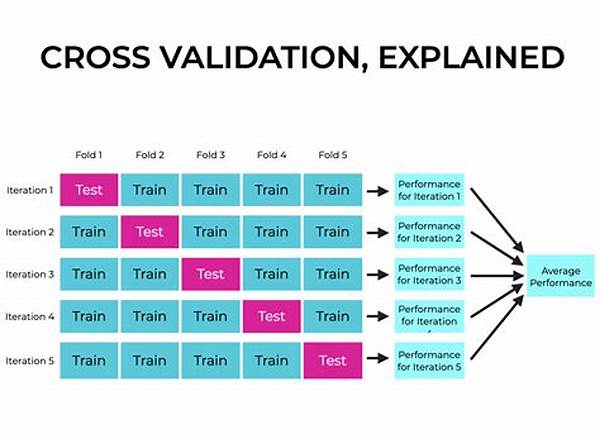
Validating models using cross-validation fundamentally shifts the perspective on how we assess models. Instead of a one-off test that might not account for various data peculiarities, cross-validation divides the dataset into multiple subsets known as “folds.” You then train your model on a combination of these folds and test it on the remaining ones, thereby making sure that each data point has had its moment in the analytical spotlight. This inclusive approach offers a more holistic view of your model’s performance, ensuring you don’t miss critical insights hidden in the data.
Incorporating cross-validation in your workflow doesn’t just minimize errors—it maximizes your data’s potential. Imagine the satisfaction of knowing that your model has been refined to its optimum level of performance, like a perfectly tuned guitar ready to play a beautiful melody. Understanding and applying cross-validation means you’ve done your homework and are confident in what your machine-learning model brings to the table. Now, why wouldn’t anyone want that level of assurance?
Cross-Validation Techniques: A Deeper Look
At the intersection between theory and practice in data science lies a pivotal tool—cross-validation. As models become increasingly sophisticated and datasets more complex, the need for robust validation techniques becomes essential. Cross-validation fills this niche perfectly, offering a systematic approach to validating models and, in effect, future-proofing them against unpredictabilities.
Techniques such as k-fold cross-validation, leave-one-out cross-validation (LOOCV), and stratified cross-validation each offer their advantages and unique selling points. K-fold is the granddaddy of cross-validation techniques. It’s loved for its balance between bias and variance, offering a realistic measure of model accuracy. In contrast, LOOCV is the meticulous craftsman, using every single data point as a test case individually, though it might be computationally expensive. Stratified cross-validation, on the other hand, ensures that each fold is a perfect miniature reflection of the original dataset in terms of class distribution—consistency at its best!
Implementing these techniques transforms the assurance that one’s model will handle the real-world data maelstrom. It’s akin to having an exclusive backstage pass—allowing insights into the performance and resilience of your model under various conditions. So why wait for the curtain call when you can ensure a standing ovation with validating models using cross-validation?
Discovering Best Practices for Effective Cross-Validation
Cross-validation is not just another checkbox in your model validation checklist; it’s the secret ingredient in the recipe for data science excellence. However, just like cooking, it requires the right blend and timing to extract its full potential. Whether you’re serving up models in a hotshot tech startup or a bustling corporate lab, understanding best practices in cross-validation is your ticket to becoming the top chef of predictive accuracy.
Now, let’s talk shop. It’s one thing to know the techniques, but mastering their application is another beast altogether. For instance, knowing when and which technique to deploy is just as vital. The choice between k-fold and stratified techniques often depends on the dataset size and the objectives of the prediction task at hand. So how do you figure that out? Trial, error, and some scientific flair!
Imagine your model as a contestant in a culinary competition. Preparing it with arms-length knowledge and hoping for the best is akin to whipping up a random recipe and crossing fingers for a Michelin star. By understanding validating models using cross-validation techniques, you’re turning that gamble into a calculated stride toward victory, equipped with the assurance that your model is poised for success no matter the judges or trials it faces.
The Influence of Cross-Validation on Data Science
In a landscape charged with algorithms and rising expectations, mastering the art of validating models using cross-validation is a revolution in data science practice. Serving as a compass, cross-validation steers your model development in the right direction. It keeps you poised for leaps in technological adoption, ensuring that every step, from conceptualization to execution, is grounded in rigorous validation.
Advancements in AI and machine learning push the envelope daily, setting a high bar for data-driven solutions that not only predict but also inspire trust. Cross-validation serves as an endorsement of your model’s ability to scale such heights. Picture it like a high wire; without cross-validation’s safety net, the fall is assured, while with it, seamless performance and adaptation become part of the act.
In synthesizing tools and ever-expanding libraries of algorithms, the smartest thing any data professional can do is embrace the tried and tested methodologies that scrutiny offers. In the end, validating models using cross-validation is more than just part of a routine—it’s a testament to deep learning and sanity-checking one’s algorithms rigorously. Embrace this technique and brace yourself for breakthroughs that rewrite the data-driven stories of tomorrow.
Tips for Successful Model Validation Using Cross-Validation
Employing validating models using cross-validation is an art that balances rigor with the adaptability needed in today’s dynamic data environments. The fundamental aim is to avoid overfitting while ensuring the model is resilient enough to tackle unforeseen data challenges. It’s a trusted ally in the journey to derive meaningful insights and implement strategies that lead to successful outcomes.
The right approach to cross-validation can further bolster your data narrative beyond expectations, motivating data scientists to think outside the box while remaining rooted in methodological soundness. So dive into the world of cross-validation, and watch as your predictive models transform from fledgling prototypes into fortified solutions standing tall amidst the ever-changing analytics frontier.