In the fast-paced world of data science and machine learning, ensuring the accuracy and reliability of your model is paramount. Imagine investing time and resources into developing a machine learning model, only to see it perform poorly on new, unseen data. It’s akin to throwing a surprise birthday party only to find out you’ve got the wrong day. Ouch, right? This is where cross-validation swoops in like a superhero to save the day. Cross-validation is a statistical method used to estimate the skill of machine learning models. By dividing data into subsets, we get multiple assessments of a model’s predictive performance. Whether you’re a newbie data enthusiast or a seasoned scientist, understanding the types of cross-validation methods is crucial.
In plain terms, cross-validation provides a window into how well your model will generalize to an independent dataset. Why is this important? Because in the world of machine learning, real-world accuracy is everything. You could develop the flashiest, most complex predictive model, but if it falls flat in the field, it’s essentially useless. Cross-validation methods give you the evidence you need to adjust, calibrate, and ultimately succeed. It’s essentially your trusted sidekick, guiding you with wisdom earned from rigorous data trials. And trust us, when it comes to predictive success, nobody wants to fly solo.
This article will delve into the intriguing world of cross-validation, examining several key types of cross-validation methods, including k-Fold, stratified, and leave-one-out cross-validation. Each has its unique strengths and characteristics, offering different insights into your machine learning model and its potential real-world performance. Whether it’s a quick and dirty proof test with k-Fold or the exhaustive thoroughness of leave-one-out, these methods cover all bases. By the end of our journey, you’ll be armed with the knowledge to select the perfect cross-validation method for your next big project, ensuring your model soars rather than stumbles.
The Dynamic Types of Cross-Validation
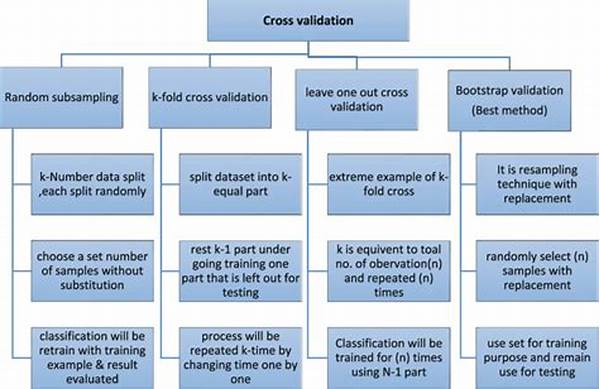
There are several types of cross-validation methods, each serving unique purposes based on the data and model requirements. One popular method is k-Fold cross-validation, where the dataset is divided into ‘k’ subsets, or folds. The model is trained on ‘k-1’ folds and tested on the remaining fold. This process is repeated ‘k’ times, allowing each fold to be the testing fold once. This method strikes a balance between bias and variance, making it particularly popular for many applications.
Another method, stratified k-Fold cross-validation, is an improved version of the k-Fold. It’s perfect when dealing with imbalanced datasets, like trying to teach a dog tricks when it only wants treats. Here, each fold retains the same proportion of classes as the entire dataset, ensuring that the model isn’t biased toward more frequent classes. By faithfully maintaining class distribution across folds, this method often results in better generalization of the model.
For those who have a need for precision, leave-one-out cross-validation (LOOCV) is the holy grail. As the name suggests, this method leaves out one data point from the dataset, training the model with the rest. While LOOCV is incredibly thorough, it’s also computationally expensive and can be slower than a sloth on a lazy day. Each method offers unique insights, helping ensure that your models not only predict outcomes with scalpel-like precision but do so with the wisdom of experience.
Exploring k-Fold Cross-Validation
One of the most frequently employed types of cross-validation methods, k-Fold cross-validation, is cherished for its robustness and efficiency. Why is it celebrated like a Saturday night pizza party? Because it reduces variance compared to other forms and provides a more accurate picture of model performance. With k-Fold cross-validation, the concept is simple yet effective. The dataset is divided into ‘k’ equal subsets, and the magic of machine learning begins there.
A major advantage of k-Fold is its versatility. Regardless of the size of your dataset or the complexity of your model, k-Fold can be tailored to fit seamlessly. When ‘k’ equals 5 or 10, this cross-validation method strikes an effective balance, providing reliable performance metrics without demanding too much computational power. It’s like finding that perfect pair of jeans — always reliable, always fitting just right.
However, while k-Fold cross-validation has its merits, it’s not the holy grail for every task. A potential downside is its need for multiple training sessions, which might be cumbersome for massive models. Nonetheless, with its propensity to provide a comprehensive evaluation coverage, k-Fold cross-validation remains a top-tier method when assessing the predictive prowess of machine learning models.
—
When diving deep into machine learning, you’ll quickly encounter various types of cross-validation methods. These aren’t just fancy buzzwords but intricate techniques that impact your model’s performance. Think of them like multiple flavors of ice cream – each providing a unique taste and experience in validating your model. The purpose of cross-validation is to evaluate how the model will perform on an independent data set, allowing for a reliable estimation of the model’s accuracy on unseen data.
One might ask why all the fuss over these methods? Because without them, you’d be like a blindfolded painter, creating art without seeing the colors. You want every line of code, each data point, to weave together into a masterpiece. Statistics speak volumes; even a staggering increase as small as 3% in prediction accuracy can translate into big wins in business and research. Still doubting? Picture this: you’re an online retailer predicting customer purchases. An accurate model isn’t just a tool; it’s a ticket to increasing profits, optimizing inventory, and retaining customers.
The emotional appeal of these types of cross-validation methods resonates with the notion that no model can afford to be imperfect. You’ve invested heavily in collecting data, curating it, and feeding it into sophisticated algorithms. So why settle for anything less than accuracy? With cross-validation, you build a bridge connecting raw data and actionable insights.
Among popular methods are the k-Fold, which allows each subset to act as a testing set; leave-one-out, known for being extensive; and stratified k-Fold for preserving class distribution. Choosing the right cross-validation method doesn’t just test your model — it refines it, it perfects it. By strategically applying these types of cross-validation methods, you’re setting your model up for success and celebrating victories that are rooted in precision.
Kinds of Cross-Validation Techniques
Selecting the right cross-validation method is akin to picking the correct gear for a mountain hike; the path to machine learning success is peppered with obstacles only a keen data science enthusiast will conquer. Let’s explore these techniques that form the backbone of reliable model validation and see why they matter as much as the espresso shot in your morning cappuccino.
The Essence of Model Validation
The world of machine learning and data science is fast-paced and ever-challenging. With types of cross-validation methods at your disposal, you’re equipped to build solutions that are reliable and predictive. These methods are like the GPS for enhancing model accuracy, minimizing overfitting, and ensuring your predictive models remain a useful and accurate part of the data scientist’s toolkit.
—
Every data scientist knows that selecting the perfect approach from the types of cross-validation methods can immensely influence the success of their models. Here are eight proactive measures to hone your cross-validation strategy:
By employing these tactics, you’re not only building models mirroring high accuracy but ensuring longevity in their predictive power.
—
By now, you might be pondering, “What’s the significance of perfecting such cross-validation techniques?” Imagine being the conductor of a data orchestra, each note fine-tuned to play in a flawless melody of insights. Achieving high accuracy in data models isn’t an embellishment; it’s the legacy of every competent data strategist. Strategies that fail to anticipate and incorporate types of cross-validation methods are like setting up a lemonade stand in the desert – hopeful, but missing the point.
Types of cross-validation methods aren’t just theoretical debates but practical tools in the craftsman’s workshop, expanding accuracy and reliability. While k-Fold, stratified k-Fold, and leave-one-out are just a few prodigious elements of this toolkit, remember that choosing correctly is key to gaining an edge. It’s like handing a magician the wand; the magic only happens with the right wand – the right validation scheme.
When you deploy the appropriate cross-validation method, it extends beyond mere process to become an embodiment of data mastery. Whether that means refining existing methods, exploring novel applications, or iterating with promising variations, pursuing these validation techniques invites a myriad of possibilities. After all, mastering these types of cross-validation methods is not just about getting it right but ensuring every data decision leads to smarter, more precise insights.
Perfect Practice Makes Perfect
The saying, “Practice makes perfect,” rings particularly true with the types of cross-validation methods in machine learning. Consider them your training wheels, ensuring a smooth ride towards data proficiency. A well-executed validation method doesn’t just evaluate a predictive model’s performance; it signifies how these models embrace new data in shifting environments. Trust in cross-validation is not misplaced faith but a calculated step toward sustainable and scalable data solutions.
Wasn’t this journey through the types of cross-validation methods just like finding humor in spreadsheets? Lively, with surprises around each row and column, yet fundamentally essential. Whether you’re scripting the next data breakthrough or ensuring model efficacy, wield these methods wisely. They’re your arsenal, your delight – the backbone of reliable machine learning endeavors. With mastery over such cross-validation intricacies, you’re en route to sculpting data models that’ll predict, perform, and perfectionize.