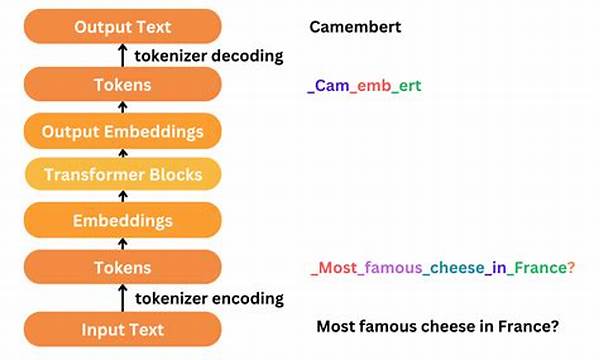
Tokenization in Text Classification
Text classification is the backbone of numerous applications ranging from spam detection to sentiment analysis. Imagine a world where your favorite email client bombards you with unsolicited spam or your movie app fails to suggest the genre you love. This is where tokenization in text classification becomes the silent hero. Tokenization is the process of breaking down a string of text into smaller, more manageable chunks called tokens. It’s akin to turning a novel into its table of contents—each chapter representing a token of words or characters—making it easier for machines to understand and analyze the text.
Tokens can be anything from a word, a sentence, to a n-gram, where n-gram represents a contiguous sequence of n items from a given text. The power of tokenization lies in its ability to transform unstructured data into structured, making it a cornerstone in preparing text data for classification algorithms. For instance, when developing a model to categorize news articles, tokenization helps in extracting meaningful features, eliminating noise, and directing the focus on what truly matters—the essence of each article. This transformation ensures that the subsequent steps of text classification, be it feature extraction or model training, are executed smoothly, leading to intelligent systems that seem almost clairvoyant in understanding vast, complex text data.
In the realm of machine learning, more data often leads to more accurate predictions. Hence, it’s crucial to allow the full potential of your dataset to shine. Tokenization in text classification plays a pivotal role in this by parsing through intricate text to retrieve essential data, enabling models to make better, faster, and more efficient predictions. By preparing your data effectively, you pave the way to creating applications that not only meet but exceed user expectations.
The Role and Impact of Tokenization
Beyond simple text parsing, tokenization is about empowerment. By harnessing the smaller yet significant pieces of information, businesses can derive insights that can drive growth and innovation. Whether it’s deciphering social media trends or enhancing customer experience through chatbot interactions, tokenization in text classification is indispensable. Ultimately, it’s the tool that turns chaos into clarity, empowering algorithms to not only see but understand the world through the lens of data.
Structuring Text Data for Classification
Effective text classification isn’t just about throwing data at a model and hoping for the best. It’s about crafting a coherent strategy that begins with tokenization.
Understanding Tokenization Techniques
Tokenization in text classification starts with this fundamental process: deconstructing text into quantifiable units. This deconstruction paves the way for finding patterns and drawing conclusions.
Despite its intricacies, the purpose of tokenization in text classification is straightforward: improve model efficacy and efficiency. But how exactly does it achieve this? By breaking the text down into tokens, irrelevant noise is filtered out while critical patterns are amplified.
In the fast-paced digital world, businesses rely on text classification to make sense of unstructured data. Here, effective tokenization serves as a table setter, dictating the success of the classification process. Consider it akin to setting the perfect foundation before constructing a building.
Taking a deeper dive, different techniques cater to varied text types. Simple word-based tokenization might suffice for basic text, but when dealing with complex scripts, subword or byte-pair encodings might be more efficient. Understanding these nuances is vital in optimizing text classification.
Practical Applications of Tokenization
Tokenization is not just confined to abstract text processing but has real-world applications. From enhancing sentiment analysis processes to shaping better user recommendations, tokenization in text classification helps companies make smarter decisions. It’s the beating heart of converting qualitative feedback into quantitative analysis.
Goals of Tokenization in Text Classification
Tokenization in text classification is often seen as just a technical necessity, but its implications go much deeper. Effective tokenization can elevate the entire classification process, offering competitive advantages especially in customer-facing applications. Regardless of the complexity of a text, from casual chat applications to formal document analyses, tokenization caters to the need for precision and clarity. Through the lens of this linguistic lens, new operational efficiencies and customer insights are unlocked.
In dynamic sectors like e-commerce, social media analysis, and digital marketing, the value of understanding user interactions cannot be overstated. Systems driven by robust tokenization mechanisms empower marketers to leverage data in unprecedented ways, crafting targeted, personalized interactions that resonate with users on a more intimate level.
By focusing on accuracy and accessibility, tokenization in text classification reduces error margins, enhances user experiences, and fosters productive client-business relationships. When messages are clear and well-targeted, conversions and engagement levels are bound to rise.
High-Level Impact Analysis
An effective tokenization strategy isn’t just about crunching numbers or segmenting words; it involves yielding transformational insights that allow businesses to anticipate trends and understand their audience. The interplay between tokenized data and sophisticated algorithms brings about a methodical shift in dealing with text, moving it from chaos to complete coherence.
Armed with robust tokenization techniques, businesses can harness the power of data-driven decisions, staying ahead of the curve. It’s akin to having a skilled translator who not only speaks the language fluently but understands the cultural nuances as well. This becomes especially crucial when user sentiments and market dynamics constantly evolve.
Conclusion
Tokenization in text classification remains a vital process in the pursuit of understanding and utilizing text data effectively. By deploying advanced tokenization techniques, businesses can gain deeper insights and construct more meaningful interactions with their audiences. Ultimately, the goal is to make data not just a static asset but a dynamic, informative partner in every step of strategic planning. The effectiveness of a data-driven approach depends heavily on how fundamentally strong the foundation of tokenization is laid.
Elements of Efficacious Tokenization
Understanding these elements ensures you’re equipped to structure your data for maximum impact. As innovation accelerates, the role of tokenization in text classification continues to expand, rendering it an indispensable tool for anyone seeking to harness the full power of textual data.
Armed with these robust methods, navigate the text universe with dexterity and precision. Whether streamlining operations or uncovering new trends, the potential of tokenization in text classification is boundless. In the end, it isn’t just about understanding text—it’s about learning to converse with data and elevating your strategic capabilities.