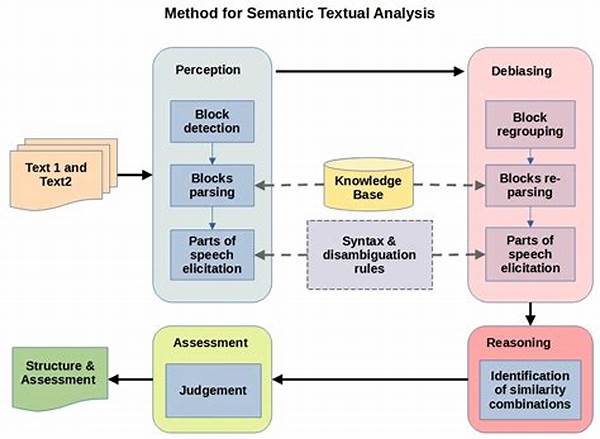
Imagine a world where computers can effortlessly understand the nuanced meanings hidden within human language. It sounds like science fiction, but thanks to vibrant innovations and advancements in Natural Language Processing (NLP), we are inching closer to this reality every day. One fascinating area within this realm is Textual Semantic Similarity Methods, which enables machines to evaluate the likeness between two pieces of text. Whether you’re a tech enthusiast, a business strategist, or someone who just loves language, understanding these methods opens up possibilities for more nuanced interactions with technology and offers the keys to the future of communication.
The journey of textual semantic similarity begins with a fundamental question: Can machines truly comprehend context, tone, and intent? Think about how you interpret texts from friends, family, or colleagues. Beyond the words themselves lies a rich tapestry of meaning shaped by cultural references, emotions, and personal experiences. For those of us in the digital age, applications that can harness this depth of understanding are not just cool—they’re game-changing.
Consider seamlessly summarizing articles, generating accurate search results, improving customer service through chatbots, or even creating content that feels truly personalized. All these applications have one thing in common: reliance on textual semantic similarity methods. Leveraging advanced algorithms, these methods empower machines to interpret meanings, making technology more relatable, functional, and indeed, human-like. The impact is already visible in various industries, driving marketing strategies, educational platforms, and even healthcare communications.
Diving Deeper into Textual Semantic Similarity
But how exactly do machines decipher our languages? One of the pivotal methods involves leveraging vector space models. Imagine words plotted in a near-infinite multidimensional space, where semantic similarities are calculated by the proximity of their respective vectors. Word embeddings, like Word2Vec or GloVe, are examples of these vector space models that capture contextual meaning and assume linguistic patterns. Each word is represented by a vector, and the angle and distance between these vectors determine their semantic similarity.
Additionally, techniques like deep learning have brought transformative changes. Implementing complex neural networks such as BERT (Bidirectional Encoder Representations from Transformers) allows machines to understand context like never before. BERT takes into account the directionality of text, which means it considers the words before and after a target word to gather context, thereby providing a more nuanced understanding. The dramatic improvement in understanding nuance, sentiment, and ambiguous language forms has garnered attention and elevated our interaction with AI to new levels.
Tools and Techniques
When it comes to employing textual semantic similarity methods, businesses and researchers utilize diverse tools and techniques. For developers, platforms like TensorFlow and PyTorch have democratized access to creating these sophisticated models. Tools such as spaCy and Scikit-learn also play a vital role in helping to design, implement, and fine-tune algorithms. Each method and tool has its unique strengths and potential, depending on the specific requirements—such as the size of the dataset, the need for speed versus accuracy, and the scalability.
In conclusion, understanding textual semantic similarity methods provides incredible insights into the future of human-computer interaction. As technology evolves, so does the richness and potential of these models, propelling us toward an era where our interactions with machines are more intuitive, natural, and effective than ever before. Embrace the world of semantic understanding, whether you’re a developer, a marketer, or simply someone interested in language, and unleash the potential buried within our digital conversations.
Key Features of Textual Semantic Similarity Methods
Understanding and leveraging textual semantic similarity methods can fundamentally transform how we engage with technology today. Consider this as an invitation to a journey where language and technology walk hand in hand, reshaping industries and enriching human experience in profound ways.