- Techniques in Feature Selection Strategy
- Advanced Methods in Feature Selection
- Techniques in Feature Selection Strategy: A Discussion
- The Role of Domain Knowledge
- Detail Points on Techniques in Feature Selection Strategy
- Structure and Strategy of Feature Selection
- Techniques in Feature Selection Strategy: Best Practices
- Insights into Techniques in Feature Selection Strategy
- Embracing Techniques in Feature Selection Strategy
- Techniques in Feature Selection Strategy: Implementational Insights
Techniques in Feature Selection Strategy
In the fast-paced world of data science and machine learning, time is money, and efficiency is key. Imagine sifting through mountains of data, trying to extract the most critical features that could define the success or failure of your model. Now, what if you could streamline that process? Enter the magical realm of “techniques in feature selection strategy.” This is not just a tool; it’s a treasure map to the goldmine of meaningful data. The essence of feature selection is to transform overwhelming data into insightful intelligence, ensuring that the model isn’t just robust but also efficient. As any data scientist will attest, having more data doesn’t always equate to better outcomes. It’s about having the right data.
Think of “techniques in feature selection strategy” as the superhero cape every data model needs. You want to fly high and fast, but you don’t want to carry unnecessary baggage. This strategy encompasses methods and practices designed to identify and retain the most beneficial features for your machine learning models. It’s like choosing the best ingredients for a gourmet dish; only the finest are selected to achieve that perfect taste. As your model’s architect, it is crucial to employ these techniques to optimize performance while minimizing the risk of overfitting or irrelevant data interference. Now, let’s delve into the thrilling tale of feature selection and discover why it’s a game-changer in the realm of data processing.
Feature selection is not merely a choice; it’s a necessity. By implementing these techniques, companies can save on computational costs and time while enhancing model accuracy and interpretability. These techniques in feature selection strategy have been tested and proven across industries, from finance to healthcare, providing organizations with a competitive edge. More data can lead to more noise, and these strategies help in filtering out the cacophony, allowing the critical information to sing through. By prioritizing relevant features, you streamline operations and create models that are not only lean but highly responsive to market changes.
Advanced Methods in Feature Selection
Diving deeper into this captivating subject, it’s essential to uncover the advanced methods that have been fine-tuned to perfection in the industry. These include methodologies like Wrapper methods, Filter methods, and embedded techniques. Each of these methodologies has its strengths and is suitable for different types of datasets and objectives. When employed effectively, these techniques can significantly enhance the prediction power of your model, turning raw data into actionable insights. It’s not just about finding which features to keep; it’s about crafting a masterpiece that tells the right story with your data.
—
Techniques in Feature Selection Strategy: A Discussion
Feature selection is foundational to the success of any data project. In a world inundated with data, it’s imperative to extract only what is necessary and beneficial. “Techniques in feature selection strategy” come to the fore to address this complexity. These techniques improve the efficiency of data models by reducing dimensionality, which in turn lowers the risk of overfitting and enhances the model’s ability to generalize insights from data. As we dive deeper into this discussion, we’ll explore some of the core techniques that have proven to be life-savers for data scientists globally.
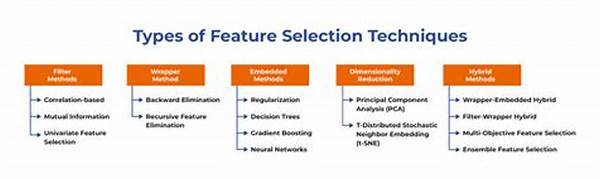
The first technique that stands out is Filter methods. These are statistical tests that evaluate the relevance of features based on their inherent characteristics, without considering any specific machine learning algorithm. This approach is simple yet powerful, giving a quick overview of which features hold the most promise. However, keep in mind that while Filter methods are excellent for initial screening, they may not capture feature interactions, which can be critical in some data contexts.
Next, Wrapper methods take center stage. Unlike Filter methods, Wrappers evaluate a subset of features based on a specific predictive model. They employ predictive accuracy as a scoring metric, iterating different combinations of features to determine which works best. This method is more computationally expensive but can yield highly tailored feature subsets. Imagine it as a bespoke suit tailored to the exact specifications of your model, promising a snug fit that ensures optimum performance.
Embedded methods bring the best of both worlds by combining aspects of filter and wrapper methods. These techniques, such as LASSO and tree-based algorithms, incorporate feature selection as part of the model training process. They are highly efficient, giving you improved performance with less computational demand. Embedded methods often strike the perfect balance by being both resourceful and effective, and are favored by many practitioners when working on large data sets.
The Role of Domain Knowledge
Rethinking Feature Importance
To truly harness the potential of “techniques in feature selection strategy,” a data scientist must be proactive about understanding the data within its context. While mathematical models and algorithms offer precision, integrating domain knowledge can drastically alter the strategy’s effectiveness. Domain knowledge helps in identifying which features align with business objectives and allows for a more informed selection process, ensuring that the data model remains relevant and insightful.
—
Detail Points on Techniques in Feature Selection Strategy
Structure and Strategy of Feature Selection
The beauty of feature selection lies in its ability to streamline processes while amplifying results. In the crowded universe of data, where more and more information is demanded daily, the significance of an effective feature selection strategy cannot be overstated. The starting point often involves an exploratory data analysis to understand the nature of the data you’re dealing with. Early detection of trends, outliers, and correlations sets the stage for a more targeted feature selection process. It’s analogous to scouting the field before the real game begins, knowing exactly where your strengths and weaknesses lie.
Upon laying this groundwork, you venture into singular techniques or a combination thereof to fine-tune your model. Understanding the nuances of each technique helps tailor your approach. Filter methods serve as a great initial sieve, while Wrapper and Embedded methods add layers of sophistication. In an organizational context, employing these strategies can be crucial for competitive advantage—allowing for faster, more precise decision-making processes that align with strategic goals. Moreover, keeping the lines of communication open between data scientists and domain experts can foster a collaborative environment that capitalizes on diverse perspectives, ultimately resulting in a more robust and insightful model.
Techniques in Feature Selection Strategy: Best Practices
Integrating Human Insight
When it comes to “techniques in feature selection strategy,” it’s critical to blend algorithmic prowess with human insight. Algorithms provide the technical foundation, but human intuition gives context and relevance. The future of data modeling is not just about machines but about a harmonious relationship between man and machine, where human judgment complements algorithmic recommendations.
—
Insights into Techniques in Feature Selection Strategy
1. Data-Driven Decisions: Guides strategic business analytics by highlighting the most significant data points.
2. Strategic Allocation: Enables better allocation of resources by pinpointing the most impactful variables for analysis.
3. Competitive Edge: Offers a competitive advantage through optimized and precise data interpretation.
4. Innovation: Stimulates innovation in model-building by opening avenues for unexplored data interactions.
5. Objective Clarity: Helps articulate and clarify complex business objectives through simplified data representation.
6. Scalability: Ensures your model remains scalable with growing data inputs without compromising on performance.
Embracing Techniques in Feature Selection Strategy
Selection techniques are the silent champions of data science. Just like how selecting the perfect playlist for a party can set the tone, feature selection carefully curates which data will lead the orchestra in your machine learning models. It’s a delicate balance of art and science, executed with precision. Understanding and employing these techniques enable data scientists to focus on quality over quantity—an adage that is as relevant here as it is in most walks of life.
Feature selection techniques include the use of algorithms and statistical measures to weed out less informative attributes, ensuring your model works with only the cream of the crop. This not only saves computational resources but also sharpens the model’s accuracy and efficacy. Corporations keen on making data-driven decisions can benefit immensely by investing in these techniques, as they lead to more focused forecasts and less muddling through irrelevant noise. Furthermore, the adaptability of these techniques allows them to mold to various sectors and data types, proving invaluable across disciplines.
Techniques in Feature Selection Strategy: Implementational Insights
The Future of Data Selection
The horizon looks promising with continued advancements in feature selection techniques. Integrating artificial intelligence and machine learning into this space will pave the way for even more sophisticated methods. The amalgamation of improved computational power with smarter, more intuitive algorithms will redefine how we approach data selection, making it an exciting frontier for data enthusiasts and tech-savvy strategists alike.
Incorporating these practices guarantees not just survival in the data-driven world but thriving success. When precision, efficiency, and innovation converge, businesses are empowered to make game-changing decisions, positioning them at the forefront of the industry.