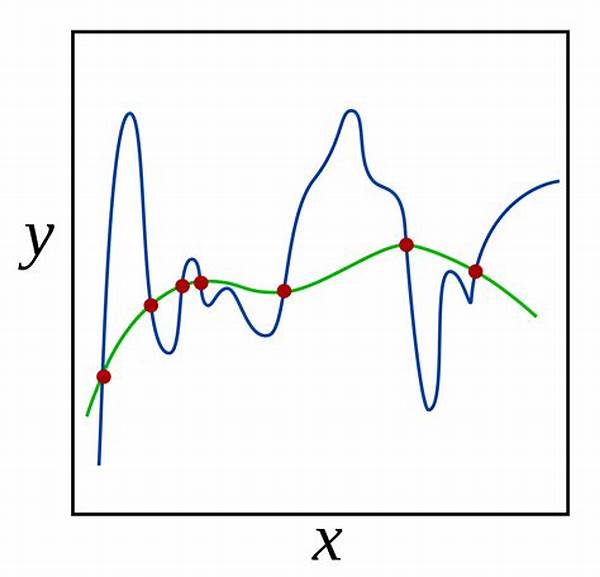
Overfitting is the arch-nemesis of any seasoned data scientist or machine learning enthusiast. It’s that sly adversary that emerges when our cherished models become too familiar with the training dataset. Imagine preparing for an exam by only memorizing practice questions; when the real test comes with its unique set of questions, you’re stumped. That’s overfitting—a model that performs brilliantly on the training data but crumbles with new, unseen data. But fear not! The world of machine learning has armed itself with regularization methods to prevent overfitting. These methods are akin to a balanced diet, ensuring that our models stay robust across any dataset they face.
Let’s talk about why this is such a buzzkill. Overfitting strikes when a model is excessively complex, capturing noise rather than the underlying pattern. It’s like trying to understand a plot by focusing too much on the dialogues without grasping the story’s essence. You don’t want your models to just parrot back the training data, but to understand its underlying structure. And this is where regularization comes into play. Regularization helps keep complexity in check. It nips the exuberant tendencies of your model in the bud by incorporating a penalty on larger coefficients within your regression model. These methods serve as gentle reminders for models to stay humble and not just memorize the training data.
Now, don’t just take my word for it—these techniques are the darling of countless researchers. They are frequently highlighted in tech blogs and forums filled with well-crafted humor and engaging storytelling. In fact, a survey of top data scientists reveals that regularization methods are among the first go-to solutions when encountering overfitting. From L1 (Lasso) and L2 (Ridge) regressions to the elusive Elastic Net, there’s a medley of approaches ready to swoop in and rescue your faltering models. Seriously, the style in which these methods are discussed can be as entertaining as a fantastic Netflix series!
How Regularization Works
Regularization works its magic by applying constraints on a model’s parameters. Take, for instance, Lasso, which promotes sparsity by driving some feature weights to zero, effectively performing feature selection. Ridge, on the other hand, applies a gentle touch, shrinking coefficients without zeroing anyone out. Regularization methods to prevent overfitting ensure that the model generalizes well by not leaning too heavily on any single feature.
The Balance of Regularization
Striking the right balance with regularization is more of an art than a science. Too much regularization, and your models underfit, unable to capture the underlying trend. Too little, and the overfitting monster raises its head again, marking its territory on your efforts.
—
Discussion on Regularization Methods to Prevent Overfitting
Overfitting in machine learning—a term that often calls forth images of complex algorithms and myriad rows of data fraught with potential for missteps. Yet, at its core, overfitting is a scenario where a model learns the minutiae of the training data to an excessive degree, becoming rather like an encyclopedic student who struggles when asked to apply knowledge flexibly. The regularization methods to prevent overfitting are the tools that recalibrate this learning process, curbing the tendency of models to latch onto noise rather than the essential signal.
Initiating a journey into the universe of regularization, one may encounter various strategies—each with its own merits and areas of application. The well-known Lasso and Ridge regressions represent two such approaches. Lasso, with its ability to eliminate unimportant features, is often likened to a sleek and nimble mover that executes feature selection with precision. Ridge provides a more moderate approach, retaining all features but adjusting the magnitude of coefficients to prevent any one feature from dominating the model’s learning.
Yet, offering these regularization methods to prevent overfitting as a panacea would be misleading. They are potent, but much like spices in a culinary dish, they require careful calibration. Apply too much, and they might mute the flavors (i.e., the model’s ability to learn vital patterns); apply too little, and they allow the overpowering taste of overfitting to prevail.
In the context of real-world applications, the effectiveness of regularization methods is well-documented. Journals and tech articles abound with case studies demonstrating significant improvements in model performance by applying these techniques. It is not merely a theoretical exercise but a battle-tested strategy that has received endorsements from data professionals worldwide. The excitement shared in forums as practitioners recount their success stories provides not just educational insights but also an emotional connection to practical triumphs in the data domain.
Ultimately, the role of regularization is not just in reshaping the learning path of models but in fostering an attitude of precision and adaptability within the data science community. These methods serve as a reminder of the complexities within datasets while promoting a disciplined approach to creating models that succeed in both testing and production environments.
Practical Implications of Regularization
Understanding the implications of regularization methods to prevent overfitting extends beyond the theoretical and into the operational. When speaking of model deployment in environments where resources are finite, regularization becomes not just a technique but a necessity to ensure models remain efficient and effective.
Real-world Insights
Accounts from various industries—from finance to healthcare—demonstrate how regularization has been the linchpin in creating models that withstand the diverse conditions of real-world data environments.
—
Key Details About Regularization
Understanding Regularization Methods
Regularization methods to prevent overfitting are vital in today’s data-driven world. In an environment where vast datasets can be both a blessing and a curse, these methods keep our models agile and ready for battle. How does one navigate this landscape, ensuring that models are not only accurate but also adaptable? With regularization principles as our guide, we can embark on data adventures with confidence.
These techniques not only correct the eager tendencies of our models but also promote a deeper understanding of the data’s true nature. By applying penalties, they trim down the unwieldy aspects of complex models, leaving us with an elegant solution that shines in varied conditions. Using such methods in combination and with mindful calibration ensures that models maintain their zest without tipping over into the murky waters of over-reliance on specific datasets.
Another critical aspect of regularization is its capacity to transform the machine learning journey into a more balanced endeavor. While data scientists often revel in building models capable of dazzling precision, regularization is the silent artist that crafts the masterpiece behind the scenes. It ensures that the model’s narrative is both compelling and coherent, an artful blend of technical prowess and resourceful data use.
Exploring Practical Approaches
In moving beyond the theoretical, let us delve into how these methods stand up to real-world scrutiny. Our models operate amidst shifting data landscapes, adjusting to new patterns as they emerge. Regularization allows them this flexibility, be it through Lasso, Ridge, or Elastic Net, each serving as a member of the machine learning theater ensemble, playing their part with flair and precision.
—
Insights and Tips for Regularizing Your Models
As we navigate the vast realm of regularization methods to prevent overfitting, data scientists and machine learning practitioners can draw from an arsenal of strategies to enhance model performance and longevity. Here are some tips to streamline this endeavor:
Embracing Regularization for Robust Models
Regularization is not merely a technical feature; it is a pathway to nurturing models that think adaptively and act accordingly. In the competitive landscape where analytical prowess dictates market leadership, regularization becomes an unsung hero subtly orchestrating success. As models evolve, it stands as both a protector and guide, ensuring they retain high performance while adapting to new datasets’ challenges.
Incorporating regularization methods into machine learning practices is akin to promoting a healthy lifestyle. It fosters resilience against unexpected data challenges and fortifies models against the over-training blues. By investing in regularization techniques, data professionals position themselves and their work at the forefront of a swiftly advancing field, ready to meet and master the unpredictable curves of the data terrain with verve and clarity.