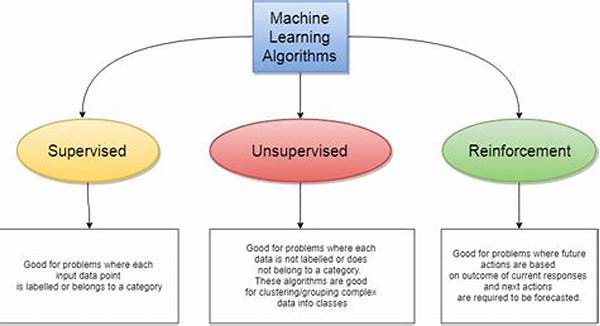
Machine Learning Algorithm Comparison
In the vibrant world of data science, machine learning stands out as a beacon of innovation and potential. From transforming mundane tasks into automated wonders to unlocking patterns that were previously hidden in complex datasets, machine learning offers a kaleidoscope of opportunities. But here lies the million-dollar question: which algorithm should you choose for your next big data venture? Enter the universe of machine learning algorithm comparison—a journey where logic meets creativity, where precision dances with intuition, and where your choice could lead to groundbreaking discoveries or magnificent flops.
It’s common for newcomers to feel overwhelmed, yet intrigued, by the sheer number of algorithms available. From decision trees that grow like curious branches to the neural networks that emulate the intricacies of the human brain, each algorithm has its own personality and quirks. This story isn’t just about zeros and ones; it’s a canvas of diverse narratives and approaches. As we navigate through this labyrinth, prepare to uncover tales of accuracy, efficiency, and the surprising results that make data science both an art and a science.
The allure of machine learning lies in its endless possibilities—an ecosystem that invites us to explore, experiment, and excel. It’s comparable to choosing a spice for your gourmet dish; the flavor profiles remind us of the algorithm traits. Decision trees offer simplicity like salt, while neural networks provide depth akin to a medley of exotic spices. Whether you’re a seasoned data scientist hungry for innovation or a curious newbie eager to dive in, this guide to machine learning algorithm comparison will whet your appetite with its blend of humor, creativity, and education.
If you’re wondering where to begin, don’t worry. Imagine a world where each algorithm has its own fan club—enthusiasts sharing their victory tales, cautionary advice, and humorous checkbox lists of do’s and don’ts. With today’s sharing culture, these narratives are not only possible but inevitable. Dive into the stories behind algorithms and get ready for a journey that promises both knowledge and laughter.
Understanding the Key Players in Machine Learning Algorithms
Machine learning algorithm comparison is not just about tallying scores; it’s about understanding the strengths, weaknesses, and suitable applications for each algorithm. Decision trees, for example, are user-friendly and perfect for those who love straightforward, interpretable models. On the other hand, support vector machines are like the sophisticated wine of the algorithm world—complex and ideal for nuanced classification tasks.
—
Machine Learning Algorithm Comparison: Breaking Down the Essentials
In the fast-evolving landscape of technology, machine learning algorithms are akin to prized tools in a craftsman’s kit. Each has its specific purpose, and understanding which to deploy is part art, part science. The vibrant conversation around machine learning algorithm comparison is buzzing with insights—be it formal debates among academic scholars or light-hearted banter among data enthusiasts at industry conferences.
Discovering the right machine learning algorithm can often feel like matchmaking. There’s an algorithm for every dataset, and just like in life, compatibility is key. For beginners, starting with linear regression or k-nearest neighbors feels akin to dating someone familiar yet fascinating; it’s comfortable, doesn’t require vast computational power, and yet delivers reliability. These algorithms are well-suited for linear problems where assumptions align nicely with real-world data.
Conversely, tackling more complex issues could require diving into the realms of ensemble methods such as random forests or boosting. These powerhouses act as the dream team of machine learning algorithms, combining the prowess of various simpler models to optimize predictions; they thrive in complexity like a seasoned explorer unearthing the secrets of uncharted territories. The robustness offered by these algorithms explains their popularity in competitions and enterprises dealing with multifaceted datasets.
No discussion of machine learning algorithm comparison is complete without homage to the giants of prediction—neural networks. Inspired by the complexity of the human brain, neural networks are behind the cutting-edge technology shaping the future: think self-driving cars, voice recognition, and breakthrough medical research. They offer flexibility and adaptability—a futuristic wonder demanding experimental prowess, large datasets, and considerable computing power.
Considering your options through machine learning algorithm comparison involves strategic discernment. Understand not just the algorithm but the problem statement, data characteristics, and computation cost. Equip yourself with research, trial and error, and leverage the vast shared experiences within the data science community. Remember the axiom—it’s not just about the hammer but knowing when to use it.
A Deep Dive into Popular Algorithms
The spectrum of algorithms involves essentials such as:
—
Identifying Core Aspects in Machine Learning Algorithm Comparison
Understanding different facets of machine learning algorithms is an exciting journey. Picture it as learning the strengths of each superhero before assembling them in your ultimate data attempting work. There is always excitement in revealing which algorithm turns out to be the unexpected hero of your data project.
When analyzing algorithms, decision trees stand out as efficient and easy-to-use. They are like that reliable colleague who always gets the work done without much fuss. Random forests and ensemble techniques build on this foundation, pooling decision trees into a ‘forest’ to produce high-performing models that are resistant to overfitting. They become the team’s all-rounders, mitigating individual weaknesses through collective effort.
Then, we have neural networks—akin to the secret weapon everyone is talking about. Neural networks are heavily researched, with their scope only limited by available data and computational resources. Their impact is transformative, enabling breakthrough advances in various industries, from autonomous vehicles to groundbreaking medical diagnostics. This makes them functional yet ambitious additions to your machine-learning toolkit.
Linear models remain a staple for those quick analysis jobs, offering the balance of simplicity and effectiveness. They may not be flashy, but often, they provide insightful clarity in complex problems with linear trends. Paired with logistic regression, they create a solid base for predictive analysis.
Rounding out the ensemble, support vector machines demand mention. Known for their clear margin in classification tasks, they handle datasets where class division is paramount with charm and precision. There’s beauty in their mathematical sophistication, making them a preferred choice for researchers and practitioners.
—
Common Features in a Machine Learning Algorithm Comparison
—
While discussing and assessing machine learning algorithms, always keep the broader picture of your specific needs and constraints at the forefront. Engage with community input, compare models, and leverage new findings shared through conferences, research papers, and even casual conversations among data science peers.
Understanding fundamental algorithm traits and how they align with your project’s story creates not just a successful data model but a thrilling chapter in your data science endeavors!