H1: Loss Functions in Neural Networks
In the rapidly evolving world of artificial intelligence, neural networks have emerged as the pinnacle technology with broad applications ranging from image and speech recognition to game development and autonomous vehicles. Among the myriad components that influence the efficacy of these powerful models, one element stands out as particularly pivotal: loss functions in neural networks. This critical concept plays an indispensable role in fine-tuning the algorithms that underpin machine learning processes. Our exploration of loss functions in neural networks will unearth their multifaceted nature and underscore why understanding them is crucial for anyone looking to excel in AI technology. This article will dissect their significance, different types, and the profound impact they hold in determining the performance of neural networks.
When venturing into the world of neural networks, one cannot help but be fascinated by their ability to mimic human thought processes. Yet, much like humans, sometimes they need guidance—a means to correct themselves when they stray from the desired path. Enter the loss function. Acting as a navigational compass, loss functions in neural networks play an instrumental role in guiding models towards achieving supreme accuracy. Whether you’re a budding data scientist or a seasoned AI researcher, wrapping your mind around how these functions operate is a game-changer.
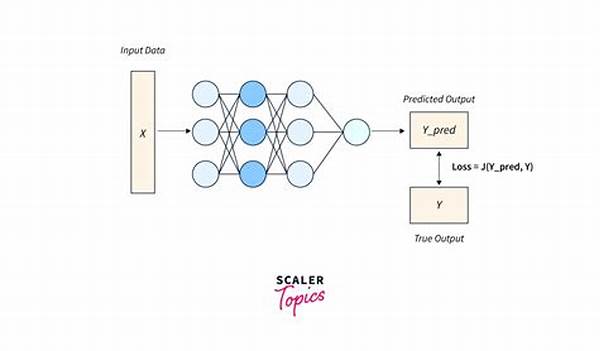
The first step in understanding loss functions in neural networks involves appreciating their foundational purpose: to quantify the difference between predicted outputs and true outcomes. Commonly viewed as a bridge between data and model predictions, they serve as the ultimate test of a network’s prowess. In essence, the smaller the loss, the more accurate the network. Popular loss functions include Mean Squared Error for regression tasks and Cross-Entropy Loss for classification tasks, each tailored to address specific challenges and optimize performance.
Despite their technical nature, mastering loss functions in neural networks doesn’t have to be daunting. With consistent practice and by leveraging online resources, one can demystify these complex algorithms. Consider them your trusty AI mentor—guiding and improving your model iteration by iteration. By understanding these elements and knowing how to choose the right loss function, you position yourself at the forefront of intelligent systems development, propelling your projects to new heights.
H2: Different Types of Loss Functions
—
The Building Blocks: Purpose of Loss Functions
Before diving deep into the sea of neural networks, one must comprehend the cornerstone upon which these technological marvels stand. At its core, understanding the purpose of loss functions in neural networks is paramount. These mathematical constructs quantify the error or ‘loss’ between the actual and predicted outcome, serving as the feedback mechanism that informs a model how far off its predictions were. By doing so, they allow for the iterative refinement of models, tuning them towards optimal performance and ensuring they generalize well when faced with unseen data.
The identification and application of appropriate loss functions in neural networks depend heavily on the problem at hand. For instance, regression problems often employ Mean Squared Error, a function that emphasizes large errors by squaring them, thus amplifying their impact on the loss value. This approach helps neural networks take significant corrective steps, aligning closely with their objective. Conversely, classification problems frequently utilize the Cross-Entropy Loss owing to its efficacy in measuring the discrepancy between two probability distributions. It’s these targeted applications that set the stage for transforming basic neural setups into sophisticated models.
H2: Analyzing Impact and Selection
Choosing the most suitable loss functions in neural networks transcends simply grasping their purpose. It involves a meticulous analysis of each function’s impact on the training process. Given the diverse nature of tasks at hand—ranging from image classification to natural language processing—the task of selecting an optimal loss function is one of balancing computational efficiency with predictive accuracy. Inadequate selections can lead to prolonged training times and subpar performance, whereas informed, strategic choices often amplify a model’s capacity for learning and adapting to data.
To add a layer of complexity, one must remember that each architectural tweak in a neural network can alter its behavior. For instance, deploying activation functions such as ReLU or Softmax can interact differently with certain loss functions, sometimes necessitating a switch. Thus, a dynamic approach, one that involves constant evaluation and refinement, remains central to leveraging loss functions effectively. By doing so, enhanced performance, reduced overfitting, and robust model predictions come into play, marking a successful foray into neural network optimization.
H3: Future Trends in Loss Functions
As we journey into the deeper realms of AI, it’s evident that innovation continues to shape the future of loss functions in neural networks. The rapid advancements in machine learning and AI denote a trend towards specialized, task-specific loss functions crafted to handle nuanced challenges—be it addressing fairness or improving interpretability. This surge in relevance is undoubtedly driven by an ever-evolving landscape that demands precision without compromise. Consequently, these advancements promise to redefine how neural networks integrate into future applications, opening avenues yet to be explored.
Imagine a world where loss functions anticipate the challenges of the dataset themselves, adjusting dynamically in real-time. Or consider the potential for hybrid loss functions that amalgamate multiple objectives into one cohesive form. These tantalizing prospects hint at a future where loss functions evolve from mere backdrops into key players in the integration and success of AI technologies. For those adept at wielding these tools, the rewards are boundless—ushering in an era where human ingenuity and machine precision meld seamlessly to redefine what’s possible.
—
H2: Ten Crucial Discussions About Loss Functions
In diving into loss functions in neural networks, it becomes apparent just how impactful these components are in the vast tapestry of AI. These functions hold the power to determine whether a neural network will thrive or flounder, making them worth discussing and understanding comprehensively. Engaging in critical conversations about their role in shaping AI advancements reveals the intricate nuances hidden beneath the surface.
The exploration of loss functions forms a key part of ongoing research and analysis within machine learning. Researchers aim to decipher how these functions might evolve to accommodate forthcoming technological shifts and demands. Through expert interviews and case studies, the continued dialogue offers glimpses into the challenges and triumphs embedded in fine-tuning these functions.
What remains crucial, then, is not only understanding but also actively navigating the expansive world of loss functions in neural networks. Doing so promises to unlock myriad opportunities—bestowing upon data scientists and AI enthusiasts the ability to enhance performance, maximize efficiency, and most importantly, continue innovating within this burgeoning field.
H2: Navigating Loss Functions: Tips for Success
Navigating the multifaceted domain of loss functions in neural networks involves blending technical expertise with strategic decision-making. As these functions serve as the backbone for model training and optimization, approaching their selection demands a grounded understanding of task requirements. Prioritizing functions that harmonize with your specific problem type ensures a crucial alignment between goals and execution.
Simultaneously, equilibrium in precision and performance marks another essential consideration, where balancing computational costs alongside model accuracy is key. This balance is achieved through iterative testing and refinement, ensuring chosen functions remain optimally functioning as your model evolves. Beyond these foundational aspects lies the critical need to embrace innovation, staying abreast of loss function advancements and broadening expertise by learning from seasoned professionals. By doing so, one can look towards building robust, intelligent neural networks capable of excelling amid the ever-evolving AI landscape.