Lack of Model Regularization Techniques
In the dynamic world of machine learning, regularization techniques often serve as the unsung heroes, enabling models to generalize well on unseen data while keeping overfitting at bay. However, a surprising lack of model regularization techniques can often lead to disastrous results, from erroneous predictions to inefficiencies, or worse, complete failure. Machines are getting smarter, it’s true, but without the checks and balances that regularization provides, their intelligence can spiral out of control. Understanding which regularization technique to apply, and when, marks the difference between a model that merely seems accurate and one that truly understands the nuances of the data.
Imagine an overconfident machine, with its learning hinges on every nuance in the training data like a student who memorizes answers without understanding the question. This lack of model regularization techniques can bloat the model and, ultimately, lead to futile endeavors in uncovering valuable predictions. To any data scientist worth their salt, understanding this concept is akin to possessing a map that unveils the treacherous seas of machine learning, where models rise and fall based on their capability to predict the future without clinging to the past.
In the arena of business, creative strategies can introduce tension and finesse to stay ahead. Similarly, adding regularization techniques injects the right balance into models, allowing them to withstand real-world scenarios. Think about running a marathon. Would you rather sprint full force only to exhaust yourself halfway, or pace your strides cleverly, reaching the finish line victoriously? Here, pacing equates to the regulated approach of model tuning through regularization. Yet, the reality is that many still neglect the vital nature of these techniques, and the assumption of data richness often pushes developers to treat regularization as an afterthought rather than priority.
Understanding Regularization
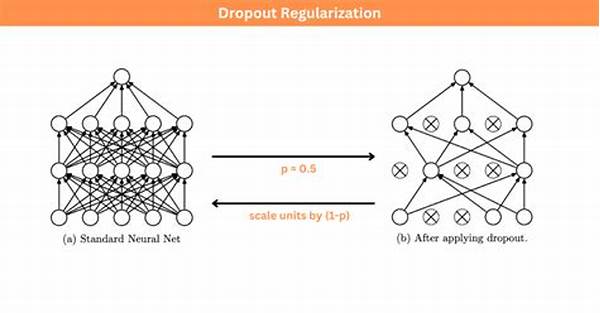
What makes regularization so compelling is its ability to fine-tune models. Essentially, regularization incorporates additional information to penalize or use constraints on the complexity of the models. The goal is elegant: reduce variance (overfitting) by imposing some form of cost on the complexity of the model. Concepts like L1 and L2 Regularization, dropout, or even early stopping, form the bedrock on which robust models stand. The lack of model regularization techniques therein can render even the most sophisticated neural architecture practically impotent.
Picture a chef seasoning their dish. The right amount enhances flavor, but missing regularization is akin to over-seasoning; it ruins the meal. In parallel, lack of model regularization techniques often results in models that lack robustness when tested under varying input conditions.
Consequences of Skipping Regularization
Skipping regularization isn’t just risky, it’s often economically unsound. In competitive landscapes, having a nimble and adaptative model delivers a clear edge. Overlooking regularization propagates inaccuracies leading to diminished ROI, whether in resource allocation, predicting consumer behavior, or anticipating market shifts. Want your model to sing? Allow it to understand the essence of music through regularization rather than treating it like an uncontrolled orchestra where every instrument plays at once.
Exploring the Road Less Traveled
In this narrative dominated by fierce rivalry and constant innovation, it’s easy to think solving for one aspect solves all. Yet, the lack of model regularization techniques underscores a deeper need for harmonizing practicality with theoretical efficiency. Building from the ground up, evaluating techniques beyond the conventional, embracing diversity in methods—even emotional decisions become key. Our models, just like us, benefit from a touch of philosophy: understand what’s necessary, discard the rest, and savor the elegance of simplicity.
Call to Action
Whether you’re just starting on this mesmerizing journey of data science or have sailed these waters for some time, revisit and reanalyze your approach to regularization. It’s time to stop neglecting the fundamentals. Upon this endeavor, contemplate, evaluate, and respond by implementing suitable methods to the work at hand. Engage with communities, read further, and test theories. In the fascinating sphere of predictive modeling, regularization isn’t a choice—it’s a cornerstone. Embrace it, lest your innovations be short-lived.
Unpacking Regularization for Effective Model Building
The role of model regularization in achieving effective and accurate machine learning models is influential yet often underestimated. This article extends an invitation to delve further into the landscape of regularization, touching upon its need, best practices, and potential roadblocks. However, the landscape is not without its gaps, and one of the most critical issues is the lack of model regularization techniques—a problem that demands our attention.
The Need for Regularization
In an ideal scenario, a machine learning model learns the underlying patterns of the data, forming a holistic understanding and an ability to generalize effectively. It is here where regularization finds its importance. When a lack of model regularization techniques prevails, models fall into overfitting traps, and unmanageable results do surface.
The art of balancing bias and variance is more than a theoretical notion—it’s a pragmatic technique crucial in real-world applications. Regularization methods embody this balancing act, imposing penalties on complex models and promoting simpler hypotheses. This tact not only aids in refining model performance but also prevents the model from stretching itself too thin by adapting too strictly to the training data.
Unraveling Complexity with Regularization Methods
To embark on this exploratory journey is to understand the versatility of regularization methods. Consider L1 and L2 techniques, where model coefficients meet subtle constraints to avoid excessive fluctuations. Each approach—be it elastic net, ridge, or even dropout in neural networks—illustrates unique dynamics. Nevertheless, an unawareness or lack of implementation signifies an area where data scientists can indeed advance their practices.
When data scientists identify and address the lack of model regularization techniques, they build resilience. Models become less about precision within training scope and more about navigating the uncharted territories of future predictions.
Optimize Your Models: The Promising Tools of Regularization
The promise of regularization is real. From improving predictive power to lifting the lid on new data interpretations, the conversation on model regularization cannot be sidelined. It remains a tool that converts raw potential into transformative insights. Organizations benefit exponentially by engaging with this decisive factor, gaining access to refined predictions and actionable strategies.
Presenting regularization as an available “off-the-shelf” solution fosters the urgency to fill the lack of model regularization techniques. It’s about championing efforts that bridge the chasm between theoretical assumptions and practical deployments.
Ignite Interest with Testimonials & Research-backed Insights
Emulating the success of industry leaders employs a role model tactic vital to reinforcing regularization’s merits. Consider organizations that have bravely tackled regularization gaps; soliciting stories from data pioneers can both inspire and educate. By diving into case studies and collaborative initiatives, best practices emerge with the clarity to resonate and revamp existing frameworks.
Through embedding regularization as a staple element of machine learning models, data enthusiasts start converting conversational topics into actionable strategies. Here, knowledge transforms evolving awareness into practical application.
Tap into Resources and Community Power
From research papers and datasets to online forums and tutorials, the abundance of information on regularization techniques is within reach. Gathering knowledge from these resources empowers data professionals. It encourages experimentation without fear of failure, fostering an environment where learning aligns with application, even in domains that suffer from the lack of model regularization techniques.
As a closing note, it’s evident: regularization propels forward-thinking innovation. It embeds versatility, stability, and adaptability within models, building them into structures capable of redefining possibilities.
—
Key Discussions on Lack of Model Regularization Techniques
In today’s data-driven landscape, recognizing the power of regularization is a game-changer. Despite its importance, many practitioners grapple with the lack of model regularization techniques, risking potential pitfalls and suboptimal results. Regularization offers a toolkit for enhancing model simplicity without foregoing performance, making it indispensable in data science applications.
The pressing need is for data scientists to not only grasp regularization concepts but also deploy them adeptly. One way to combat this shortfall is by promoting comprehensive training modules and facilitating forums that unify the community around shared experiences. As stories of regularization successes circulate, the staggering transformation becomes not just theoretical but palpably real. Emphasizing these successes can bridge the knowledge gap, allowing individuals and organizations alike to sidestep errors and capitalize on newfound efficiencies.
Deep Dive into Regularization Practices
Regularization remains an instrumental component in ensuring that machine learning models perform well beyond their training datasets. Yet, in the grand pursuit of accuracy, a lack of model regularization techniques can have adverse effects, stunting potential growth and agility in applications.
Carving Pathways in Regularization
Taking a thoughtful approach to regularization involves embracing what these techniques can offer. At its core, regularization manages overfitting by imposing constraints or penalties, nudging a model towards simplicity while retaining performance. Examining different techniques offers routes to explore Elm streets versus grand boulevards. Each has its role and understanding situational appropriateness is key.
Models without regularization become akin to the prodigy unprepared for real-world challenges. While initially promising, sustainable success demands more depth than merely relying on academic prowess. The experience of integrating regularization can provide a real-world toolkit that models need to thrive sustainably.
Addressing the Challenge: Practical Solutions
A variety of solutions can address the lack of model regularization techniques in practice. First, investigation into regularization options should become routine, not relegated to hindsight. Second, broadening the scope beyond basic regularization lends depth to machine learning practices, paving paths untrodden by complacency or tradition. Third, build vital networks by fostering interdisciplinary discussions around regularization strategies, unveiling hidden potentialities within complex data landscapes.
Shaping the Future of Model Building
Do not underestimate the profound impact of addressing these gaps. With every iteration, models optimize predictive power, writing the future with multitudes of untold intelligences. Regularization thus acts as a catalyst for change, bringing data-driven insights to new horizons.
Unlocking the Next Generational Leap
Ready to shift gears from theoretical muses to agile adaptability? Regularization shoulders much of this transformation. Now is the time for recalibration, reprioritization, and rapid deployment of regularization across landscapes where intelligence collaborates with creativity. So let’s seize the initiative, advancing where data whispers demand directions boundless yet profound.
Essential Steps for Advancing Regularization Techniques
Informing practitioners about novel techniques and foundational concepts ensures progress.
Evaluating test scenarios against structured outputs showcases regularization’s efficacy.
Embracing multidisciplinary projects fosters innovative practices.
Propagating tools specifically designed for regularization supports expressive modeling strategies.
Integrating regularization into industry standards instigates long-term shifts.
Inviting community input and shared experiences enhances collective understanding.
Historical case studies unravel patterns instructive for modern-day applications.
Systematic approaches anchored in best practices safeguard reliable output.
—
By comprehending the techniques woven within regularization, new architectures evolve from fledgling concepts to industry benchmarks. Deeper integration fosters resilience amidst complexities, navigating diverse datasets sans the framework of overfitting constraints. As we pivot toward deepened analytical insights, a notable corollary exists: the insights predate their time yet rely disruptively on what underlies—our grasp of regularization steerages future ascendancy.