In the exuberant world of machine learning, where algorithms often swim in a sea of data, regularization serves as a life buoy. Among the plethora of techniques available, L1 and L2 regularization techniques stand out as the aficionados’ choice to balance model complexity and predictive performance. These techniques are akin to a splash of humor in a dry, technical conference; they lighten the model and sharpen its predictions. Whether you’re launching your new startup, aiming to defeat the demons of overfitting, or just exploring the labyrinth of linear regression, L1 and L2 regularization techniques offer the golden touch.
Let’s reel you into the jigsaw of regularization. Imagine fitting a model that excessively hugs data points, capturing noise instead of meaningful patterns. This is where L1 and L2 regularization techniques waltz in, promoting a model that is lean and mean, able to generalize beyond the training data. L1 regularization, also called Lasso, gingerly trims the excess by adding a penalty equivalent to the absolute value of magnitudes of coefficients. It’s like Marie Kondo clearing the clutter, keeping only what sparks joy—or in this case, what genuinely contributes to predictions.
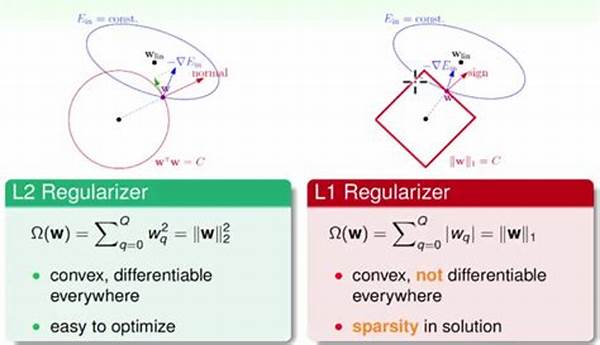
L2 regularization, known as Ridge regression, is equally stellar and suave, taming the wild coefficients by applying a penalty on their squared magnitudes. Think of it as a meticulous tailor, ensuring every measurement is in perfect harmony. Together, these techniques elevate the model into a well-oiled prediction machine, capable of sifting through complexities while sidestepping overfitting with grace and finesse.
The Power of Regularization in Machine Learning
L1 and L2 regularization techniques are like the unsung heroes of the AI saga. Their ability to enhance model performance while maintaining interpretability is unparalleled. Imagine having the superpower to influence not only models’ accuracy but also their efficiency and clarity—much like a seasoned marketer who knows just the right touch to seal the deal. These techniques are particularly beneficial when handling high-dimensional data, as they help in feature selection and prevent the model from becoming overwhelmed by irrelevant variables. It’s like having a GPS that guides your model through the dense forest of data to arrive at a clear, actionable insight.
Regularization stands as the guardian of generalization in the world of machine learning. It’s a concerted effort to ensure that models don’t just perform well on training data but also excel when presented with new, unseen data. Among the trove of strategies aimed at achieving this equilibrium, L1 and L2 regularization techniques are among the most prominent.
Exploring L1 Regularization: The Lasso Method
L1 regularization, fondly called the Lasso method, serves as a dynamic tool in the data scientist’s arsenal. It takes the fiery, untamed energy of model coefficients and channels it with precision. By adding a penalty equivalent to the magnitude of coefficients, L1 regularization effectively trims the model, akin to a masterful chef refining a dish to perfection, retaining only what adds flavor.
Why L2 Regularization Matters
L2 regularization complements L1 by applying penalty adjustments to the square of the coefficients, ensuring that every prediction stands sturdy, akin to a well-fortified castle. Its strength lies in creating models that are not just accurate but consistent, resonating with the rational, detail-oriented analyst who seeks perfection in precision.
“The Resilience of Regularized Models”
In practice, L1 and L2 regularization techniques lead to resilient models that embody not only the power of precision but also the beauty of balance. They ensure that machine learning models emerge as both potent predictors and robust analyzers. For anyone venturing into the realm of data science, adopting these techniques is less of a choice and more of a necessity, guiding the path to insightful, impactful results.
Leveraging the Benefits
The primary aim of employing L1 and L2 regularization techniques is to enhance model generalization. As we plunge into the specifics, it’s essential to recognize how these techniques serve a dual purpose: they cut through the complexity of data while ensuring the model retains its interpretative power.
Shedding unnecessary weight from the model, L1 regularization effectively streamlines it, preserving only relevant features. This leads to models that produce not just accurate results but insightful analyses, where every coefficient tells a unique story—a treasure trove for marketers seeking impactful narratives.
On the other hand, L2 regularization ushers stability and harmony, smoothing out fluctuations that could otherwise lead models astray. It’s like tuning a musical instrument, ensuring each note hits precisely, captivating the audience with its pristine sound. This balance, found in the heart of L2, promotes optimal performance amidst tumultuous data variance.
The very ethos of L1 and L2 regularization techniques aligns with crafting models that stand the test of time. Such choices in technique transform data into actionable insights, not just guiding decisions but accelerating strategies toward success.
Implementing Regularization for Success
To fully seize the benefits, deploying L1 and L2 regularization techniques must be an iterative and informed journey. Collaborating with knowledgeable peers or consulting with expert data scientists can enhance understanding and application. This blend of action and insight fosters an environment where data-driven decisions thrive, unlocking potential that propels projects to new heights.
With every algorithm fine-tuned and optimized via these techniques, the overarching goal is achieved—models that not merely understand data but also communicate insights, heralding a future where machine learning continuously evolves, smarter, and faster. Dive into the intricate dance of regularization, and watch as your models flourish, speaking the language of precision with assertive eloquence.
Mastering L1 and L2 Regularization Techniques
Unlocking the power of L1 and L2 regularization techniques doesn’t just stop at mere understanding; it requires mastery. As you sail the ocean of machine learning, these techniques become the trusty compass guiding your ship. Picture this: you’re a data-driven explorer, venturing into uncharted territories with confidence and precision.
Frequently Asked Questions About L1 and L2 Regularization
Mastery involves asking the right questions. Understanding what L1 and L2 are, how they function, and when to apply them is crucial. With L1’s feature selection prowess and L2’s balancing act, these techniques become indispensable tools, a cybersecurity expert’s encryption, ensuring the safety of your models against overfitting.
The beauty of L1 and L2 regularization lies not just in their technical prowess but also in their intellectual elegance—helping create models that are not just powerful but profoundly impactful. Embrace these techniques; let them illuminate your data journey, and inspire others to join the realm of optimized, intelligent modeling.
Six Tips for Optimal Use of L1 and L2 Regularization
Investing effort into understanding these techniques is a strategic challenge. Properly applying L1 and L2 regularization techniques allows data enthusiasts to sculpt highly efficient predictive models, minimizing errors. Thus, as you subtly intertwine humor and education in your endeavors, let regularization be your silent but mighty ally.
Every step you take along this path unveils a new layer of comprehension, leading to insightful revelations and breakthroughs in model accuracy. Regularization becomes not just an addition to your strategy but the backbone of a robust, modern machine learning approach, enabling the vast potential of data analytics to be unlocked and harnessed effectively.