- H1: K-Fold Cross-Validation for Better Models
- H2: Getting Started: Implementing K-Fold Cross-Validation
- H2: The Purpose of K-Fold Cross-Validation
- H3: Achieving Precision and Reliability
- H2: Ensuring Better Outcomes with Minimal Errors
- UL: Examples of K-Fold Cross-Validation Applications
- H2: Unveiling the Magic of K-Fold Cross-Validation
- H3: Building Trust in Model Predictions
H1: K-Fold Cross-Validation for Better Models
In the fast-paced realm of data science and machine learning, one frequently hears tales of a powerful tool that ensures models not only run efficiently but accurately too. Today, it’s time to unravel the mystery surrounding k-fold cross-validation, a technique that’s quickly moving from buzzword to necessity. You might reminisce about the era when data scientists were like magicians, conjuring models out of thick data clouds, hoping they’d hit the bullseye on unseen data. Alas, optimism alone rarely yields results. That’s where k-fold cross-validation for better models comes into play. Imagine having a finely-tuned compass guiding your model training. This compass divides your data journey into multiple segments, ensuring every rough terrain is tested and accounted for.
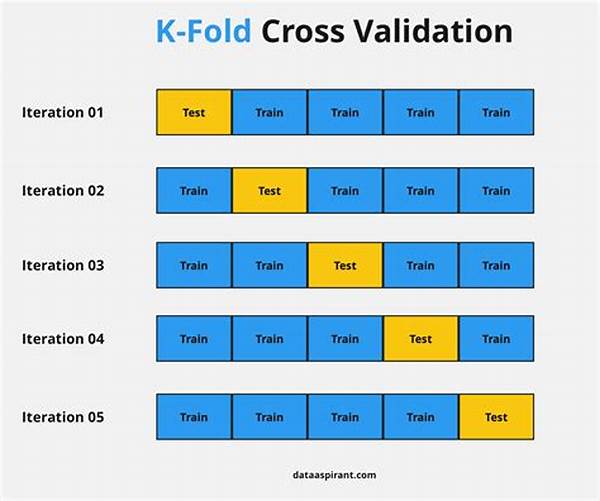
In this article, we’ll delve into how this splendid tool works in practice. Start with dividing your dataset into k subsets or ‘folds’. You train the model on some and validate it on the remaining ones. This process is repeated k times, ensuring equitable exposure for each data chunk in both training and validation phases. It’s akin to a chef seasoning a stew, ensuring every ingredient gets its moment of glory. By the end of these rotations, the model boasts a robust report card – a true reflection of its performance.
Now, you must be wondering how k-fold cross-validation for better models can revolutionize your data insights. The secret lies in its prowess to minimize overfitting. By spreading the data love across folds, the model learns to generalize better, sidestepping common pitfalls like training bias. In a world hungry for precision, this method sets your models on a path to precision, even amid eclectic datasets.
H2: Getting Started: Implementing K-Fold Cross-Validation
More than a fancy technique, k-fold cross-validation is a ticket to credibility in the modeling world. Dive into resources, participate in workshops, and soon you’ll wield this tool with finesse. In today’s competitive market, where everyone claims to have the best model, k-fold validation serves as your trusted ally, ensuring that your claims are backed by rigorous testing and authenticity.
—
H2: The Purpose of K-Fold Cross-Validation
The primary aim of k-fold cross-validation for better models is to provide a robust framework for evaluating the generalization performance of machine learning algorithms. By meticulously dividing the data, the model gets a comprehensive exposure across various segments. This technique is highly sought after because it offers a more reliable estimate of model performance compared to simple train-test splits.
H3: Achieving Precision and Reliability
K-fold cross-validation paves the way for achieving precision in model predictions. With each fold carefully curated to represent the overall dataset, it ensures that each data point gets its chance to influence the model’s learning. The ripple effect of this is a model that’s not just accurate but also reliable across unseen data instances.
In today’s fast-evolving tech landscape, where every company aspires to harness the power of artificial intelligence, k-fold cross-validation for better models stands out as a quintessential practice. It empowers data scientists to transform data hordes into actionable insights, elevating model trustworthiness and improving decision-making processes. Behind the scenes, this technique is the unsung hero, offering stability in an ever-changing digital world.
H2: Ensuring Better Outcomes with Minimal Errors
The essence of k-fold cross-validation for better models is its ability to minimize prediction errors. While traditional methods may often lead models astray, especially in the case of nuanced datasets, k-fold cross-validation comes to the rescue, ensuring accurate predictions every step of the way. In this regard, it acts like a meticulous detective, always on its toes, ensuring nothing slips through unnoticed.
In conclusion, adopting k-fold cross-validation for better models is more than a suggestion; it’s an imperative for those seeking to create cutting-edge models that stand the test of time. As you veer deeper into the intricate world of machine learning, remember this technique as your trusted guide, ensuring you never lose sight of accuracy and reliability.
—
UL: Examples of K-Fold Cross-Validation Applications
H2: Unveiling the Magic of K-Fold Cross-Validation
For anyone diving into the intricate world of machine learning and data modeling, k-fold cross-validation stands as a beacon of reliability and precision. Imagine setting sail on a vast ocean of data, where every wave can either propel you forward or topple your ambitions. In such a journey, consistent testing across multiple scenarios becomes indispensable. This is where k-fold cross-validation for better models shines through, offering not just insights, but a comprehensive guide to building trustworthy models.
H3: Building Trust in Model Predictions
K-fold cross-validation empowers data enthusiasts to see beyond immediate data snapshots, encouraging a broader perspective. By slicing the data pie into manageable portions, every fold gets its due attention, refining model predictions with each iteration. This isn’t just a method for the detail-oriented; it’s an essential practice for anyone serious about crafting models that won’t crumble when faced with new challenges.