Hey there, fellow data enthusiasts! Have you ever spent hours fine-tuning your model, only to realize that it’s not as accurate as you’d like it to be? If you nodded there, you’re in the right place. We’re going to dive into a game-changing method that can make your predictive models shine—cross-validation. Trust me, once you get a hang of this, improving predictive accuracy with cross-validation will feel like upgrading your old car to a sleek new ride without actually breaking the bank!
Why Cross-Validation Matters
Alright, let’s get into the nitty-gritty. Think of cross-validation as a mini-exam for your data. Rather than training and testing your model on the same dataset, cross-validation splits your data into multiple sets. This practice allows your model to be tested in a more generalized environment. Improving predictive accuracy with cross-validation ensures that your model is not just memorizing the data but actually learning from it. Picture cross-validation like rehearsing for a play by practicing in front of different groups—not only your pet cat. This technique helps in identifying the adaptability and reliability of your model, which is essential for real-world applications. So, the next time you’re knee-deep in data, remember that a solid cross-validation strategy is your data’s best friend!
Cross-validation also aids in detecting overfitting. We’re all guilty of falling into the overfitting trap now and then. It’s like cramming for an exam and acing it, only to forget everything the next day. In the same vein, cross-validation equips your model to handle unseen data without tripping up. If you want your predictive accuracy to be top-notch, cross-validation is the way to go. It’s like the ultimate workout for your predictive model, ensuring that it’s in top shape no matter what data you throw its way.
Implementing Cross-Validation Techniques
Feeling pumped about improving predictive accuracy with cross-validation yet? Let’s delve into some techniques!
1. K-Fold Cross-Validation: This is the bread-and-butter of cross-validation techniques. Your dataset is split into K parts or “folds.” Train your model on K-1 folds, and test it on the remaining one. Repeat until each fold has been used as a test set. It’s simple, yet powerful.
2. Leave-One-Out Cross-Validation (LOOCV): As the name suggests, you train your model on all data points except one, which acts as the test set. This is iterated over every data point. Although it can be a little computationally expensive, it’s super thorough.
3. Stratified K-Fold: Similar to K-Fold but ensures each fold is a good representative of the entire dataset. This is particularly useful when dealing with imbalanced datasets, helping in improving predictive accuracy with cross-validation by maintaining the same distribution of classes as the full dataset.
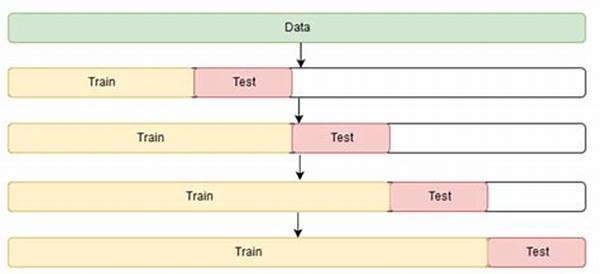
4. Time Series Cross-Validation: For time-series data, K-Fold won’t work because time series require an order. Instead, the data is split respecting the time structure. Use the past as the training set and validate on future data points.
5. Nested Cross-Validation: This involves multiple loops of cross-validation: an inner loop for model selection and an outer loop for model assessment. It’s like a meta-cross-validation process and is ideal when you want to ensure the model selection process is unbiased.
Pitfalls in Cross-Validation
While improving predictive accuracy with cross-validation is a great goal, there are pitfalls to watch out for. First up, computational expense. Depending on your dataset size and the complexity of your model, this process can be time-consuming. Your laptop might sound like it’s about to take off, so make sure you’ve charged it beforehand! But hey, think of it as upgrading your kitchen by getting rid of all mismatched cutlery—you end up with a neater, better-performing space.
Another issue is the choice of cross-validation technique. Not every technique suits every dataset. K-Fold might be the go-to, but the choice really depends on your specific context. For instance, if you’re working with highly imbalanced data, you might find stratified methods more useful to ensure that your model gets a well-rounded picture of the data distribution. It’s sort of like choosing the right filter for your coffee machine—not all brews are created equal.
Lastly, remember not to use cross-validation results as the ultimate yardstick of success. While better than simple train-test splits, the true test lies in real-world deployment. Your model might ace cross-validation but then get stage fright when facing actual data. Continuous monitoring is key to improving predictive accuracy with cross-validation and ensuring your model excels.
Benefits of Cross-Validation
You might wonder, “Why go the extra mile with cross-validation?” Simple! It helps you gauge how your model will perform in unseen situations. Improving predictive accuracy with cross-validation allows you to trust your model’s outcomes more. It’s like practicing different drills in basketball, preparing you for various game scenarios.
Not only does cross-validation help in creating a more robust model, but it also boosts confidence in your results. The end goal of any predictive modeling is to come up with insights that are actionable and meaningful. By incorporating cross-validation in your practice, you’re likely to spot flaws and rectify them before they even reach deployment. Picture it as getting feedback on your artwork—it helps refine and enhance the final product.
Also, it’s about tangible improvements. By tackling the weaknesses head-on, you see improvements in areas that matter most. Whether it’s hitting a better R-squared score or reducing mean squared error, cross-validation ensures that your model isn’t giving you rosier predictions simply by chance. You get a true reflection of how well your model generalizes to unseen data.
Real-Life Examples and Applications
Cross-validation is not just a fun concept for data nerds; it’s a need for anyone serious about applying predictive models in the real world. From finance to healthcare, improving predictive accuracy with cross-validation opens up avenues for better decision-making. Imagine a credit score model that’s more accurate and fair, or a health diagnostic tool that helps identify diseases with higher precision. That’s the real-life magic!
In retail, for example, cross-validation is used to predict customer behavior and improve personalization. If you can better predict what customers might want, you’re more likely to tailor offers they can’t resist. It’s like being able to guess your friend’s pizza toppings before they even order—magic, but backed by data science.
Marketing and sales channels already benefit enormously from improved accuracy, leading to better customer profiling and targeted strategies, thanks to cross-validation. Meanwhile, in tech companies, improving predictive accuracy with cross-validation helps optimize algorithms behind recommendation engines, ensuring users are presented with the most relevant content. It lets them turn scattered data into coherent insights, leading to strategic moves aligned with actual habits and preferences.
Conclusion
Alright, folks. What’s not to love about improving predictive accuracy with cross-validation? From creating high-performing models to detecting overfitting, cross-validation is the ultimate tool in the predictive modeling toolkit. While it does require some computational muscle and careful selection of techniques, the benefits far outweigh the costs.
If you’re diving into the world of predictive models, consider cross-validation your best ally. It’s like a trusted friend who tells you when your tie is crooked—honest, reliable, and invaluable. So next time your model doesn’t cut it, remember, improving predictive accuracy with cross-validation might be just the twist you need to turn things around. Keep experimenting, keep learning, and happy modeling!