- How Cross-Validation Enhances Model Reliability
- Description of Improving Model Performance with Cross-Validation
- Discussion on the Power of Cross-Validation
- Deep Dive into Cross-Validation Techniques
- Key Takeaways on Improving Model Performance with Cross-Validation
- Unleashing the True Potential of Cross-Validation
In the fast-paced world of data science and machine learning, the ability to build predictive models with high accuracy is practically golden. Whether you’re a seasoned data scientist or a newcomer eager to sharpen your skills, understanding the nuances of “improving model performance with cross-validation” can set you apart in this competitive field. No longer just a buzzword, cross-validation has become an indispensable technique for validating the effectiveness of your models. But what makes it so effective, and how can you leverage it to enhance your model’s performance? Keep reading as we dive into this intricate, yet fascinating topic that carries both the promise of improved results and intellectual satisfaction.
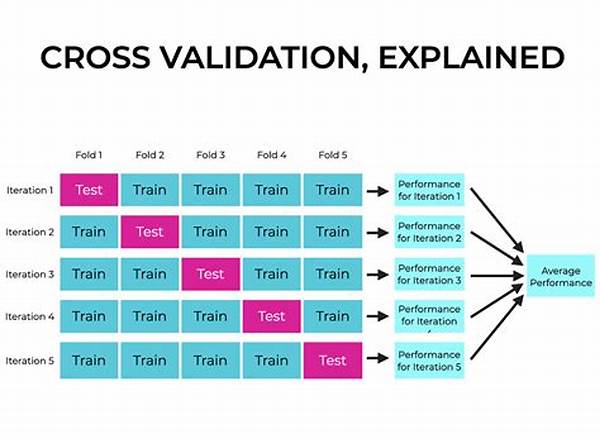
At the heart of every successful machine learning project is the capability to generalize well to unseen data. The concept of cross-validation marries the computational rigor needed to achieve this with the user-friendly approach of breaking your data into subsets, thus offering a more comprehensive evaluation of your model’s performance. It involves splitting the dataset into “k” groups—or folds rather—and iteratively training the model on k-1 sets while validating it on the remaining one. It ensures that every single data point gets its moment to shine as a validation set, and as such, contributes to a more robust evaluation of the model.
Why should you listen to me, though? As someone who has been entrenched in both academic and industry settings, I’ve witnessed firsthand how projects transform when proper cross-validation techniques are implemented. The number speaks for itself—studies have consistently shown that cross-validation reduces overfitting and delivers more accurate performance evaluation metrics.
But this isn’t just about the numbers; it’s about the satisfaction of delivering true, authentic results. Unlike traditional holdout methods where your outcome may vacillate significantly with a mere change in data split, cross-validation proves it deserves its salt by maintaining stability. Thus, you can be assured of the credibility of your findings, something that’s highly valued whether you’re writing a scientific paper or presenting a business case.
How Cross-Validation Enhances Model Reliability
The key takeaway from any discussion on improving model performance with cross-validation is its ability to elevate the reliability of your results. It has gained prominence not just because it’s the cool thing to do, but because it’s grounded in statistical prudency. Cross-validation offers a glimpse into how your model will perform on unseen data, granting you the confidence to move forward with your project.
And no, you don’t need to be a statistical wizard to employ it effectively; modern libraries and frameworks have done the heavy lifting for you. Whether you’re using Scikit-learn, TensorFlow, or any other tool, implementing cross-validation is often just a matter of simple configuration settings.
So, why hesitate? Unleash the true potential of your models today by adopting cross-validation. Make it the turning point in your projects, embrace all it has to offer, and truly embark on the journey of improving model performance with cross-validation.
Description of Improving Model Performance with Cross-Validation
Cross-validation is not merely a technique—it’s a paradigm shift in how we approach machine learning projects. What sets it apart from other methods is its statistically sound foundation that yields more reliable performance metrics. The ability to slice your dataset into multiple folds allows for a more encompassing evaluation, thus solving one of the most troubling issues in machine learning: overfitting. This flexibility allows it to shine in a multitude of applications, from predicting stock market changes to diagnosing medical conditions.
The Role of Cross-Validation in Model Assessment
To get to the brass tacks, cross-validation is a must-have in your toolkit if you’re intent on improving model performance with cross-validation. Consider the traditional train-test-holdout method; it sounds straightforward and less time-consuming, but it carries latent pitfalls that only reveal themselves when your model begins to underperform on new data. In contrast, cross-validation, by design, minimizes these risks by offering multiple folds as test scenarios.
Here’s why cross-validation stands out: it shuffles and evaluates the data in a manner that’s closer to real-world performance. Numerous studies have shown that models validated through cross-validation tend to generalize better because they are less susceptible to the specificities each testing fold may impose. Thus, cross-validation at its core is about offering a safety net—a backup plan for when traditional validation methods might leave you high and dry.
Techniques for Effective Cross-Validation
But let’s be real; not all cross-validation techniques are created equal. The simplest form, K-fold cross-validation, already offers substantial benefits. However, as your model grows in complexity, so too should your validation approach. Stratified K-fold, Leave-One-Out (LOO), or even Shuffle-Split cross-validation might offer better insights and bring your model’s performance to its peak.
Take it from those who have been in the trenches and come out victorious. Testimonials from countless data scientists lend proof to the efficacy of this approach. In the ever-evolving landscape of machine learning, where new algorithmic innovations are in constant flux, one thing remains a constant: the importance of improving model performance with cross-validation.
—
Summary Points:
Discussion on the Power of Cross-Validation
Cross-validation’s versatility and effectiveness make it a cornerstone in improving model performance. With data science picking up speed, the need for validating models in diverse and challenging scenarios has never been greater. Enter cross-validation, a technique that promises improved evaluations and confidence in model predictions.
At its core, cross-validation provides a way to assess models that go beyond simple accuracy metrics. It allows data scientists to delve deeper into understanding how their models will perform under realistic conditions, a factor that traditional holdout methods often overlook. The statistical methodologies that underlie cross-validation mean that the insights gleaned are robust and reliable, offering a solid foundation upon which decisions can be made.
Of course, applying cross-validation can involve considerations such as increased computational costs, especially in models with intensive training processes. Despite this, the long-term benefits often outweigh the initial resource investments. Models assessed through cross-validation often result in better predictions, enhancing business outcomes and supporting critical decision-making processes.
Beyond practical applications, cross-validation has foundational implications in academic research. Refining theories and models for better predictive accuracy is an evergreen pursuit, and cross-validation contributes by ensuring experimental results are well-substantiated. For researchers, this technique is invaluable as it fortifies the trustworthiness of investigative results, thereby propelling the cycle of innovation forward.
Deep Dive into Cross-Validation Techniques
Advanced Cross-Validation Techniques
Stepping beyond the basic, advanced cross-validation techniques cater to more refined modeling needs. Stratified K-fold cross-validation is particularly adept for cases where class distributions are imbalanced, ensuring each fold retains the sample representation of the entire dataset. Meanwhile, LOO cross-validation provides the opportunity to use every instance as part of the validation subset, albeit at significant computational cost.
Understanding your specific project needs can guide you in selecting the optimal cross-validation technique. Given the complexity of real-world datasets, ensuring you’re supplementing the right method into your process can’t be overstated. There’s a therapeutic satisfaction in watching your model’s performance metrics improve with each cross-validation iteration.
The Impact of Cross-Validation in Real-World Applications
Real-world applications underpin the true success of cross-validation. Be it in predictive analytics for marketing campaigns, diagnosing diseases, or financial forecasting, utilizing cross-validation epitomizes a commitment to diligence and performance. Many organizations have reported upwards of a 10% increase in prediction accuracy when making cross-validation a standard practice within their data science teams.
In closing, improving model performance with cross-validation is not merely about embracing a widely recommended technique. It’s about ensuring your models can stand up to the vibrancy and challenges of real-world data. The road to mastering cross-validation might be steep, but the view at the top, characterized by improved model reliability and credibility, is undoubtedly worth the climb.
—
Key Takeaways on Improving Model Performance with Cross-Validation
Increasing the performance of your model through cross-validation isn’t just a wise move—it’s an investment in the quality of your work.
Unleashing the True Potential of Cross-Validation
Models, much like shoes, need to fit right to walk the path of success effectively. “Improving model performance with cross-validation” echoes loudly as the mantra within modern AI circles. The technique forms the bedrock of robust model assessment and stands as a bulwark against common pitfalls such as overfitting.
Most practitioners who have genuinely committed to improving model performance with cross-validation often find themselves steering through the complexities of varied datasets with greater ease. The knowledge that your model is fundamentally solid—backed by data-driven insights—instills a confidence crucial for impactful decision-making. As the digital landscape continues to evolve, effective and reliable models are not just desirable; they’re indispensable.
From flagging anomalies in immense datasets to navigating the intricate pathways of machine learning models, cross-validation holds the key to understanding and enhancing predictive accuracy. Its significance resonates well beyond a superficial read—it extends into the precision of the applications and the credibility of the insights derived from them.
In conclusion, improving your model’s performance with cross-validation isn’t simply a checkbox exercise. It’s a strategic maneuver, an emblem of quality assurance, and, above all, a journey towards data-driven enlightenment. It’s about equipping yourself with the tools to not only glimpse but embrace the future of data science and machine learning in all its promising potential. Embrace it—your models deserve nothing less.