I’m glad to help you, but given the extent of your request, I’ll start by providing a detailed structured article about cross-validation techniques in prediction. Then, I can assist you further with other components based on your specifications, like lists, descriptions, or additional content.
—
In the rapidly evolving world of data science and machine learning, model accuracy is king. It’s the Holy Grail we’re all chasing, the secret sauce that ensures our predictions match reality as closely as possible. But how do we ensure that our models are truly performing at their best, instead of simply fitting well to a specific dataset? Enter cross-validation, the not-so-secret weapon that data scientists wield to ensure robust and reliable predictive models.
Cross-validation is a statistical technique used to estimate the skill of machine-learning models. This technique is particularly useful in situations where the data available is limited, which is often the case in real-world scenarios. What cross-validation does is essentially partition the data into multiple subsets. In turn, the model is trained on some subsets, while the remaining subsets are used to validate the model. This process repeats several times with different combinations of partitions to ensure the model’s robustness.
Imagine you’re a chef trying to perfect a new recipe. Instead of testing your dish on the same group of friends every time, you invite different folks over for a taste test, each bringing their unique palate, to give you comprehensive feedback. Cross-validation operates on a similar principle, thereby ensuring that our model isn’t just a perfect fit for a one-time scenario but can predict accurately across the board.
Now, while cross-validation can seem quite technical, its benefits are vast and incredibly relevant in today’s data-driven universe. It aids in combating overfitting, the notorious villain where a model might perform exceptionally well on training data but falls flat when applied elsewhere. Through cross-validation techniques in prediction, we are given the armor to not only protect against these pitfalls but to emerge on the other side with a model that’s generalizable and reliable.
Unpacking Cross-Validation Techniques
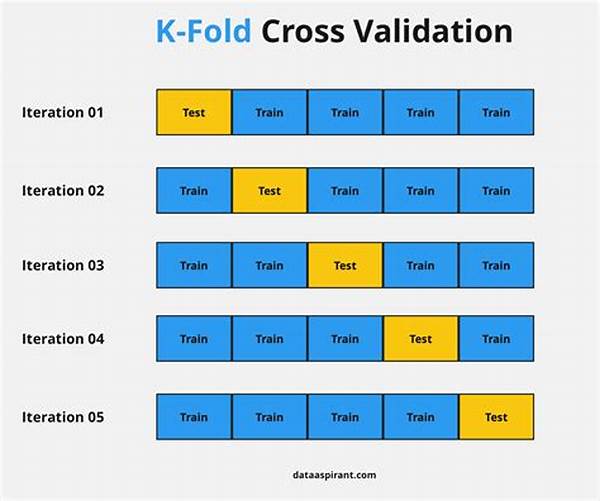
Let’s dive deeper into the world of cross-validation techniques in prediction. The most classic method is k-fold cross-validation, where the dataset is split into ‘k’ subsets, and the model runs multiple times with each of these parts serving as the validation data exactly once. But, there’s more on the menu! You might stumble upon leave-one-out cross-validation, which, as the name suggests, reserves one data point for validation and the rest for training. Then there’s stratified k-fold, which maintains the same distribution of classes in each fold. Each offers its unique spin and utility.
Cross-validation is not only about reducing errors but also about bolstering confidence in your model’s performance. As a storyteller shares tales by reaching into varied experiences, a good model should be able to shine under different circumstances. Therefore, using cross-validation techniques in prediction helps ensure your model isn’t a one-trick pony.
However, before diving in, remember this – cross-validation, while powerful, requires careful consideration of computation resources. Each fold requires a full model training cycle, which, while giving more insight, demands more in terms of processing power and time. But fear not! The benefits of ensuring your model’s veracity often outweigh these costs.
Lastly, remember that behind every great model predicting user behavior, market trends, or disease outbreaks, lies the unassuming yet mighty cross-validation. It helps us sit back with confidence, knowing our kitchen concoctions will win over any crowd, no matter the taste preferences or prior biases.
—
If you need additional sections like lists, headers, short articles, or specific writing styles, let me know which part you’d like expanded on or revised!