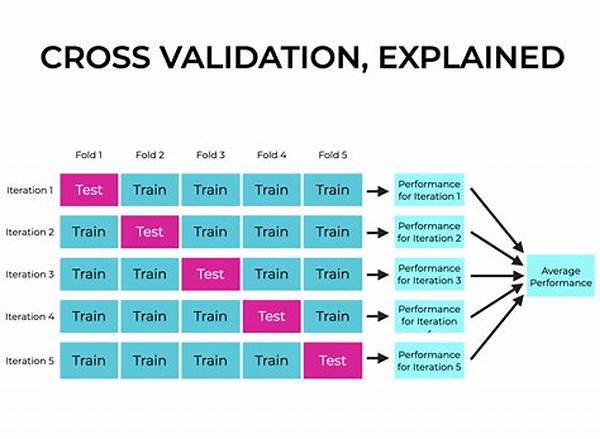
Cross-Validation for Model Validation
In the world of data science and machine learning, ensuring the accuracy and reliability of predictive models is a pivotal task. One might concoct the most intricate of algorithms, yet without proper validation, it remains akin to wandering about in an unfamiliar neighborhood without a GPS. Enter the hero of our story: cross-validation, a powerful method that shines a spotlight on model robustness and effectiveness. Cross-validation for model validation is not just a technical practice but a knightly quest to enhance prediction accuracy while minimizing overfitting, ensuring that models not only perform well on training data but also on unseen data.
Imagine you’re planning a grand party. You’ve prepared a fabulous playlist (your model) based on past hits (your data). You’d want this playlist to resonate well across diverse audiences, not just your inner circle. Cross-validation is like road-testing this playlist among different groups before the big event. By segmenting data into multiple parts and iteratively testing different sections, anything out of tune is identified and replaced with fresh tracks, ensuring the final mix is universally appealing. Therefore, cross-validation for model validation is not just a process but an art form in perfecting the ensemble.
The magic of cross-validation lies in its ability to emulate real-world scenarios within a contained environment. It compensates for limited data by making full use of available information. This mighty technique is the antidote to overfitting—a situation where the model learns the noise rather than the signal within the data. By employing various methods such as k-fold, stratified k-fold, leave-one-out (LOO), or time-series split, cross-validation for model validation ensures a rigorous examination of the model’s generalization capabilities across different stages of data.
Techniques and Strategies in Cross-Validation
The landscape of cross-validation is vibrant, showcasing an array of strategies suited for different modeling scenarios. K-fold cross-validation is perhaps the most popular—it splits the data into k segments, training the model on k-1 folds and validating it on the remaining one. This is repeated k times, with each fold used once as a validation while others are used for training. However, this is but one approach amongst the arsenal, each with unique strengths and tailored utilities.
—
Descriptive Insights into Cross-Validation for Model Validation
Cross-validation, much like a vantage point from a hilltop, provides a panoramic view of how a model performs across various datasets. Imagine having the ability to test-drive a car before purchasing to determine how it runs on different terrains—cross-validation for model validation offers similar peace of mind for data scientists and machine learning engineers. It explores the unseen alleys of data interaction and ensures that the model doesn’t merely memorize the current landscape but understands the lay of the land.
Understanding the Necessity
The necessity of cross-validation stems from the core principle of generalizability—models should be robust enough to make accurate predictions not just on known data but also on new, unseen datasets. Without such a validation process, you might feel confident about a model only for it to falter in real-world applications due to overfitting or underfitting. Cross-validation for model validation acts like a reality check, ferreting out the hidden shortcomings that pure testing might overlook.
Implementing Cross-Validation
Implementing cross-validation is akin to conducting an orchestra, each section of data playing its part toward a harmonious performance. With well-configured pipelines, one can seamlessly integrate this validation step into the model-building process, leveraging tools available in various libraries such as Scikit-learn. The adoption of cross-validation methodologies ensures a balanced harmony between training prowess and practicality in actual deployment.
The adaptability of cross-validation offers a tailored approach to suit different types of data structures and availability, providing versatility and robustness. Whether it’s classification, regression, or time-series analysis, cross-validation for model validation is the universal joint that connects data preprocessing to model evaluation, yielding detailed insights about bias-variance trade-offs and ultimately guiding toward improved decision-making.
Key Points of Cross-Validation for Model Validation
—
The Art of Cross-Validation for Model Validation
Cross-validation in model validation serves as an insurance policy for data scientists, offering a profound verification method that instills confidence in predictive models. Picture this process as a dress rehearsal before a major theatre production, where every scene is evaluated to ensure a flawless opening night. It’s not just about checking facts but preparing the model for the myriad faces of data it will encounter once deployed.
The Underlying Necessity
The fundamental necessity for cross-validation stems from its ability to portray a realistic appraisal of how a model will fare in the real world, plagued by unseen data variance and potential noise. It’s akin to prefacing a journey by examining possible routes to the destination, each with different traffic patterns, ensuring the journey is both swift and smooth.
Methodological Approaches
Diverse methodologies like k-fold and stratified k-fold are akin to multiple lenses, each offering a unique view and cutting through the fog of uncertainty that can cloud model validation. Cross-validation for model validation doesn’t merely affirm correctness; it also pinpoints potential areas for improvement, acting as a roadmap to refine algorithms until they’re battle-ready to join the fray in real-world applications.
Another practical aspect is procedural simplicity, which assures data scientists that adopting cross-validation methods into their workflow will result in minimal disruption while maximizing the efficacy of validation efforts. This ease of implementation, supported by robust libraries and tools, transforms this meticulous evaluation into a straightforward yet powerful operation.
Ultimately, the essence of cross-validation for model validation lies in its philosophical alignment with the data science gold standard: models should foresee, not just see. It compels us to look beyond the confines of training datasets, extending our horizons to understand how models might stand up to the unforgiving nature of raw, real-world data.
Advantages Beyond Validation
Cross-validation promotes a culture of continuous iteration, where every outcome is a learning opportunity—an invitation to adapt and fine-tune. It fosters a scientific curiosity, urging data scientists to explore ‘what if’ scenarios, an exercise that can reveal unforeseen patterns and relationships within data. Through the lens of cross-validation, model validation is elevated from a mere checkpoint to a crucible for innovation and discovery.