- Why Cross-Validation Matters
- Different Techniques of Cross-Validation
- Common Challenges and Solutions in Cross-Validation
- Deep Dive: Understanding Different Cross-Validation Techniques
- The Impact of Cross-Validation on Model Performance
- Implementing Cross-Validation in Practice
- Wrapping Up: The Power of Cross-Validation for Better Model Generalization
Hey there, fellow data enthusiasts! If you’re like me and find joy in turning raw data into insightful models, then this post is just for you. Today, we’re diving into the fascinating world of cross-validation and how it can pave the way for better model generalization. I know, I know, anything with the word “validation” sounds like it involves a lot of math and brain work. But trust me, cross-validation for better model generalization is not just a fancy term for making your model more robust; it’s an art form that every machine learning enthusiast should master. So, grab a cup of coffee (or tea if that’s your thing) and let’s get geeky!
Why Cross-Validation Matters
So, why should anyone care about cross-validation for better model generalization? Imagine you’ve built this model that you’re super proud of. You pop the champagne, only to realize it performs poorly on new data. Ouch, right? That’s where cross-validation comes in. By using this method, you’re essentially splitting your data into multiple parts, running your model several times, and ensuring it isn’t just memorizing the data it’s been fed. Cross-validation allows you to assess how the results of a statistical analysis will generalize to an independent data set.
This means better accuracy and reliability when you’re dealing with the wild, wild world of unpredictable data. The beauty of cross-validation is it trains the model on various splits of the dataset and then validates it on the remaining data. This dance continues until the model has been vetted through several cycles, ensuring it can perform when it counts. In short, cross-validation for better model generalization turns your model into a data ninja.
Different Techniques of Cross-Validation
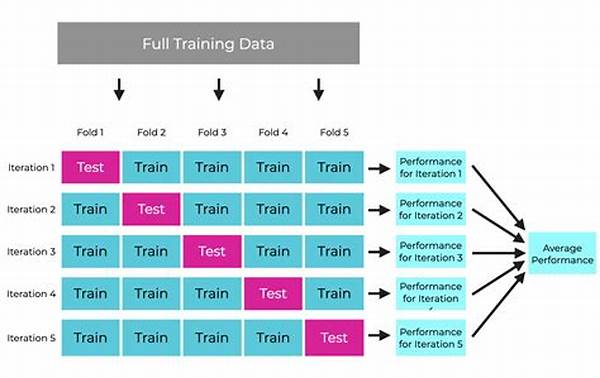
1. K-Fold Cross-Validation: Split your dataset into ‘k’ parts. Train on ‘k-1’ and validate on the remaining. Great for minimizing overfitting and helps achieve cross-validation for better model generalization.
2. Leave-One-Out Cross-Validation (LOOCV): Here, ‘k’ is equal to your data size, leaving one out each time for validation. Ensures minute details are considered for achieving cross-validation for better model generalization.
3. Stratified K-Fold Cross-Validation: Perfect for imbalanced datasets, ensuring each ‘k’ split has the same distribution of outcomes, enhancing cross-validation for better model generalization.
4. Time Series Cross-Validation: Designed for time-dependent data. It respects chronological order while enabling cross-validation for better model generalization.
5. Repeated K-Fold Cross-Validation: Simply k-fold, but on loop! Great for adding variance and reliability, thus ensuring cross-validation for better model generalization.
Common Challenges and Solutions in Cross-Validation
Navigating through the world of cross-validation for better model generalization can sometimes feel like unraveling a complex puzzle. One common hurdle is computational cost. Running multiple iterations for large datasets can weigh heavy on resources. However, cloud computation and parallel processing can cut down on time and resources significantly. Think of them as your trusty superheroes swooping in to save the day.
Another challenge? Data leakage. It’s the sneaky villain that can quietly skew your results, leading to overly optimistic performance estimations. Keeping your validation data entirely unseen until the final evaluation is the golden rule to dodge this pitfall. That way, cross-validation remains effective, and you’re not caught off guard when your model encounters a new set of data.
Deep Dive: Understanding Different Cross-Validation Techniques
Venturing deeper, let’s chat about the nuances of different cross-validation techniques. K-fold cross-validation, as discussed, is the go-to choice for most scenarios because it balances bias and variance trade-offs efficiently, paving the way for cross-validation for better model generalization. LOOCV, while meticulous, is computationally expensive and might not always be practical for larger datasets.
Stratified cross-validation, on the other hand, is a game-changer for imbalanced data, ensuring each class is proportionately represented across splits. In the realm of time-series data, respecting the order of data points is critical, making time series cross-validation invaluable. Lastly, repeated k-fold gives an extra layer of validation by running multiple iterations, ensuring your model isn’t leaving any stone unturned in its quest for generalization.
The Impact of Cross-Validation on Model Performance
Now, let’s talk about how cross-validation for better model generalization impacts overall model performance. By deploying it, you’re training your model to be more adaptive. Think of cross-validation as an intense training program for your model, preparing it to face the unknown — just like how a diligent athlete trains before a big game!
Apart from boosting accuracy, cross-validation also helps in identifying the model parameters that are genuinely contributing to its success. This, in return, simplifies the model, making it more interpretable and less prone to the overfitting monsters lurking in dark corners. Ensuring that your model holds up in the real world should always be the end game, and cross-validation is that crucial step towards achieving it.
Implementing Cross-Validation in Practice
Enough talk, let’s walk the walk and implement cross-validation for better model generalization in real life! Roll up your sleeves and pull up a Jupyter Notebook (or your preferred coding platform). The beauty of cross-validation lies in its simplicity when using popular libraries like Scikit-learn. A couple of lines of code, and boom — you’re on your way to model optimization town.
Understanding the implications of each technique and choosing the right fit for your dataset will help avoid common pitfalls. For instance, if you’re working with imbalanced data, stratified folds are your best bet. For time-series data, use time-ordered cross-validation. And remember, experimenting with different methods and parameters will give you insight into not just one model’s performance but how adaptable it is across variations.
Wrapping Up: The Power of Cross-Validation for Better Model Generalization
In a nutshell, cross-validation for better model generalization is your secret weapon in the data science toolkit. It’s the bridge that connects model development with real-world applicability. Think of it like this: without cross-validation, your model might look great on paper, but cross-validation ensures it performs just as well when facing unforeseen challenges.
So next time you find yourself building a model, remember — don’t just train it; cross-validate it. Your future self, and those who rely on your insights, will thank you. Keep experimenting, keep validating, and may your models be ever generalizing!