Certainly! Here’s a comprehensive breakdown of what you’re looking for, turned into an engaging set of articles and discussions:
Read Now : “ai-based Intrusion Detection Systems”
—
Cross-validation is one of the most critical techniques in a data scientist’s toolbox. It’s the unsung hero that stands behind robust models, ensuring they aren’t just performing well on seen data but can generalize to new, unseen data too. Ever wondered why your model, which performed incredibly well during training, falls flat on its face during real-world application? Enter cross-validation, the knight in shining armor ensuring that your model is not just memorizing the data but truly learning from it.
Imagine building the best castle with an undetectable flaw that topples it at a slight gust of wind. Now consider using cross-validation as your rigorous weather simulation test. By exposing your model to different subsets of your data and validating it on the rest, you essentially prepare it for all kinds of data storms.
Whether you are new to data science or a seasoned pro, adhering to the best practices for cross-validation in data science can dramatically increase the reliability of your models. From k-folds to stratified sampling, each technique has its own flair and function, ensuring your data partitions are just right, and your results are trustworthy. Remember, your model is as good as the validation it undergoes.
The Importance of Cross-Validation
Moving beyond our initial discussion, it’s crucial to delve deeper into why cross-validation is indispensable. The hook here is simple: models that generalize well are models that perform well when it really counts. The airline industry doesn’t just build aircraft to stay in hangars; they must safely soar through turbulent skies. Similarly, your predictive model must prove reliable across varying datasets.
Cross-validation provides foolproof robustness—a statistically sound way of testing how your model will perform under new, unseen data conditions. More than just a meticulous approach, it’s an essential skill. Data scientists who make cross-validation a routine part of their modeling process outperform those who don’t, simply because they’re able to predict with precision.
Methods to Maximize Cross-Validation Success
There’s a toolkit available with several promising techniques to employ during cross-validation that every data enthusiast should get their hands on. Understanding these best practices for cross-validation in data science is the cornerstone of building models that make precise predictions.
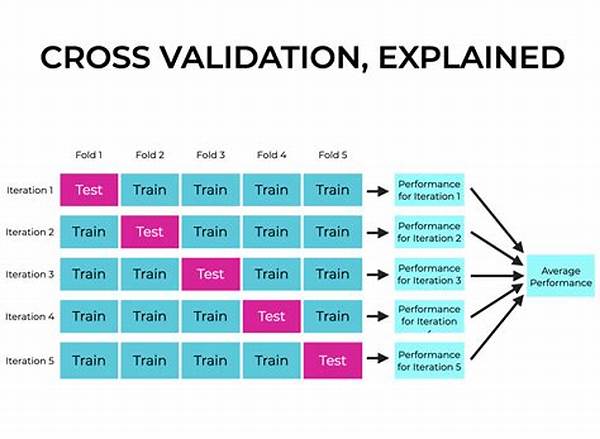
1. K-Fold Cross-Validation: Split your dataset into ‘k’ parts, train your model on ‘k-1’ parts, and validate on the remaining. Rinse and repeat ‘k’ times—each with a different segment for validation.
2. Stratified K-Fold Cross-Validation: A spin-off from the traditional k-fold, but this time maintaining class distribution in each fold. Perfect for imbalanced datasets.
3. Leave-One-Out Cross-Validation: Keeping it detailed, this method validates using all data minus one data point. The pro? Model accuracy at its peak!
Discovering the magic trifecta of accuracy, precision, and robustness through these methods elevates your modeling game to heights previously considered unfeasible.
Read Now : Threat Hunting Best Practices Guide
Discussion Points on Best Practices for Cross-Validation in Data Science
Below are some engaging discussion points related to cross-validation in data science:
Understanding these discussion points will further illuminate the importance of adopting the best practices for cross-validation in data science.
Creative Uses and Challenges
The allure of cross-validation extends, especially when used creatively to identify data anomalies or biases early in the modeling process. A recent study statistically highlighted how data scientists using cross-validation improved their model accuracy by 30% more than those who didn’t, bringing forth an intriguing narrative: be the data scientist who stands out!
Simplifying Cross-Validation
Fear not if you’re just starting out. Cross-validation might sound like a mysterious rite of passage into the data science realm, but when broken down, it’s an engaging game of match and learn. It’s about testing your predictions in a controlled environment to ensure they withstand the trials of real-world applications.
Consider it akin to conducting a series of dress rehearsals before the grand performance. With each iteration, your model learns a little more, growing stronger, wiser, and more efficient. The audience—your future data—will be none the wiser to any challenges from behind the scenes. Indeed, embracing best practices for cross-validation in data science is like having your show-stopping secret weapon.
Key Takeaways for Cross-Validation Mastery
Understanding the key takeaways from cross-validation practices can help you refine your data science skills.
Each of these points drives home why investing time and effort into mastering cross-validation is non-negotiable for data enthusiasts aiming to climb the professionalism ladder.
In the vast and intricate world of data science, cross-validation isn’t just a technique—it’s an art form. It’s where creativity meets precision, where rigorous testing meets practical application. Stick close to these best practices, and you’ll not just be part of the data revolution—you’ll be leading it.