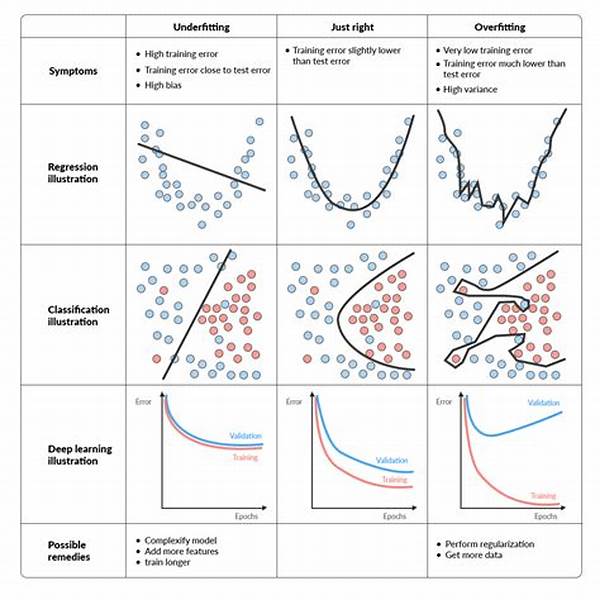
In the exciting world of machine learning, balancing bias and variance is crucial for creating models that generalize well to unseen data. It’s like walking a tightrope, where leaning too much on one side leads your model to either oversimplify or overfit the data. Bias represents the error introduced by approximating a real-world problem, which might be complex, with a simplified model. Variance, conversely, refers to how much the model’s predictions change when trained with different subsets of data. For aspiring data scientists and seasoned professionals alike, mastering this balance is the secret sauce to building effective predictive models.
Imagine you’re a detective piecing together a complex puzzle. Too much bias means you’re overlooking critical clues, crafting a narrative that’s too simplified and missing the depth of the true story. On the flip side, too much variance is like getting swept up in every minor detail, leading to a tangled narrative full of false leads. Balancing bias and variance in models ensures you not only solve the puzzle but also craft an accurate and compelling story. The goal is to find that Goldilocks zone—not too hot, not too cold, but just right—where your model is both precise and adaptable.
Model tuning is akin to conducting an orchestra, where every musician (or hyperparameter) must be finely tuned to create harmony. Overfitting models resemble a lavish symphony gone wrong, with too many solo performances drowning out the melody. Underfitting, however, lacks the complexity and creativity to ever become memorable. Balancing bias and variance in models is the art of directing this orchestra, ensuring each part contributes to a coherent and elegant performance that resonates with data and delights stakeholders.
Techniques for Balancing Bias and Variance
Understanding the Trade-off
In understanding the mechanics behind balancing bias and variance in models, one must delve into the trade-off itself. Imagine adjusting the knobs on a radio; you’re constantly seeking to reduce noise (bias) while finding that perfect station signal (variance). The interplay is delicate, and much like radio signals, data can throw you curveballs with volume spikes and whispered echoes. Techniques like cross-validation, regularization, and ensemble methods are your tools for tuning in and achieving that audio nirvana.
—
Unveiling the Mystery
In the vibrant realm of data science, understanding how bias and variance interplay can be as thrilling as unraveling a detective’s greatest mystery. The intricate dance between these two forces can feel like a mystery novel unfolding before your eyes—full of unexpected turns and pivotal revelations. Why each piece fits where it does becomes clearer when you’re mindful of balancing bias and variance in models. Harnessing this balance often requires taking a hypothesis-driven approach, testing different model complexities, and measuring their performance meticulously.
As you navigate this labyrinth, you’ll realize that no single solution fits all scenarios. It’s like being given a series of lock combinations. Each model might represent a new set of locks, and the successful ones unlock insights hidden within the data. Engaging with bias and variance allows you to mix artistry with analytics, crafting solutions that speak volumes amid silence and bring clarity amid chaotic signals.
The Art of Mastery
Tools of the Trade
Mastering the art of balancing bias and variance in models requires a toolbox full of analytical techniques and intuition. Picture a seasoned chef in the kitchen—each tool from the knife to the spatula represents a strategic method like decision trees, random forests, or Bayesian models. The recipes? They are variations of training sets that serve exquisite results when cooked at just the right parameters and conditions. Like spices, hyperparameters when wielded right, can transform ordinary data interactions into extraordinary insights, leaving stakeholders craving more.
Applying the Lessons
Remember grandpa’s old mechanic workshop with its familiar scent of oil and tools ready for the next challenge? Balancing bias and variance in models is somewhat like grabbing the right wrench to adjust a stubborn machine. It’s both an art and a science, requiring the precision of expert handiwork combined with an innovative flair for problem-solving. Each model iteration is like tweaking a vintage car, where every bolt tightened brings it closer to peak performance, gliding smoothly across the racecourse of real-world data challenges.
Actions for Balancing Bias and Variance
—
Introduction
In a world dominated by data, achieving the perfect balance between bias and variance in models represents a pivotal challenge for data scientists. This dynamic dance between reducing error and naivety while capturing the intricacies commemorates a balance celebrated by specialists and novices alike. Picture an artist with a blank canvas—balancing bias and variance is akin to carefully choosing the colors and brushstrokes to depict the subject matter with both accuracy and flair.
It’s easy to get lost in algorithms and numbers, neglecting the human element of intuition and experience. Just as a master painter knows when a stroke is enough, a data scientist discerns when a model achieves that delicate balance. This balance isn’t only critical in producing accurate results; it’s fundamental in building trust with stakeholders who rely on these models to inform decisions equally grand and granular. In the grand storyline of data, balancing bias and variance in models paints a picture of predictability and accuracy that resonates with the beat of business acumen.
Navigating this journey, we find ourselves akin to authors of a scientific saga. Each model tells a story—a narrative crafted not just from data points, but from the insight-driven strategies that balance prediction precision with pragmatic abstraction. The synergy of thorough understanding and practical application propels us into a future teeming with possibilities, where data-driven decisions pave the way for innovation and discovery.
Methods for Achieving Balance
Tips for Balance
Balancing bias and variance involves adopting strategies that optimize model precision and reliability.
Embrace the journey and equip yourself with the knowledge and practice to effectively balance these critical aspects, transforming the way data tells its story.