AI Training Data Preparation Process
In the rapidly evolving landscape of artificial intelligence, data is the new gold. Yet, raw data, in its unrefined form, resembles a diamond in the rough—it lacks luster until it undergoes meticulous processing. This journey from crude data to finely tuned AI models highlights the significance of the AI training data preparation process. With businesses eager to leverage AI for competitive advantage, ensuring the quality of training data has never been more crucial. It’s akin to a chef selecting the finest ingredients; the dish’s outcome depends heavily on the initial selections. Thus, data preparation is not just a technical necessity—it’s a strategic imperative. As AI continues to revolutionize industries from healthcare to finance, understanding the nuances of the AI training data preparation process can significantly influence the success of AI initiatives. Dive into the tale of transforming data into intelligence and discover why the preparation process is both an art and a science.
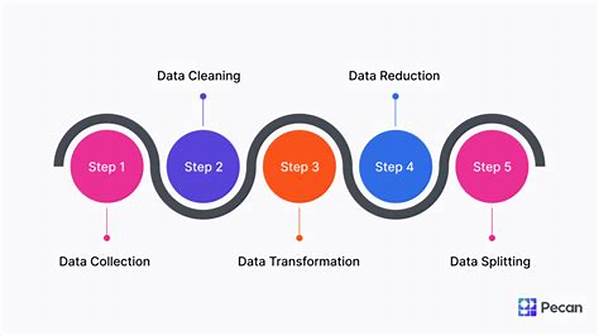
In the first phase of the AI training data preparation process, data collection lays the foundational bedrock on which AI models are built. Diverse data sources, whether structured or unstructured, need to be pooled together to provide a comprehensive training ground for machine learning algorithms. This step is akin to gathering voices from a global choir, each contributing unique notes to the symphony of AI.
Once collected, data must be cleansed and prepped, much like a sculptor chiseling raw stone into a masterpiece. Duplicate entries, inconsistencies, and anomalies are identified and rectified to ensure the accuracy and reliability of the training data. This phase requires precision and patience, akin to a detective meticulously piecing together clues to solve a mystery.
Following cleaning, data augmentation plays a critical role in enhancing the dataset. Techniques such as data transformation, image manipulation, and synthetic data generation are employed to bolster the dataset’s diversity and robustness. By refining the data through augmentation, the AI model is better equipped to generalize from its training.
A final but crucial step is the data annotation process, which imbues data with meaning and context. Labels are assigned to the data samples, providing the AI models with the semantic understanding necessary to make informed predictions. This phase transforms raw data into a knowledgeable entity, ready to fuel AI’s quest for human-like intelligence.
The Significance of Proper Data Preparation
The AI training data preparation process is not just a sequence of steps; it’s a comprehensive guide to unlocking the full potential of intelligent systems. Each stage of the process contributes to creating a robust AI model capable of delivering accurate insights and driving innovation across various domains.
—
The Discussion on AI Training Data Preparation
When unraveling the complexities of AI, one might find themselves entranced by the transformative power of robust data. The AI training data preparation process is at the heart of this transformation, shaping how AI systems learn and evolve. Just imagine trying to teach a child to read without a dictionary—it’s the same as an AI without well-prepared data. The data preparation journey begins with an understanding of the inherent value that well-prepared data brings to AI systems.
The Value of Effective Data Preparation
In our digitally rich world, data sprawls across various domains, from social media blips to financial transactions. Harnessing this data into a usable form is the crux of the AI training data preparation process. Researchers have revealed that poor data quality can lead to a 40% degradation in AI performance. Therefore, data preparation is not merely a back-end operation; it is a value-adding strategic step that shapes AI effectiveness.
Navigating Common Data Challenges
The AI training data preparation process navigates myriad challenges, akin to navigating through a maze of chaotic data points. Incomplete data, inconsistencies, and biases can obstruct the training of AI systems, rendering results misleading or inaccurate. It requires a symbiotic collaboration of domain expertise and technological finesse to address such pitfalls and channel raw data into a form that AI can comprehend and learn from.
In tackling these challenges, some organizations deploy automated tools to streamline the process. Automating repetitive data cleaning tasks not only saves time but ensures consistency and minimizes human error. However, the human touch is indispensable, especially when curating data context and understanding nuances that machines might overlook.
The most delightful part of the AI training data preparation process is witnessing the transition from chaos to clarity. When data, once scattered and nonsensical, becomes a cohesive dataset ready to be fed to machine learning algorithms, it’s nothing short of magic. Here, the blend of human ingenuity and technological prowess indeed crafts wonders.
—
Essential Steps in the AI Training Data Preparation Process
Structure for an Effective Data Preparation Process
Balancing meticulous data preparation with creativity demands a structured, yet flexible approach. Organizations might picture it as orchestrating a symphony, where each instrument—in this case, each step—plays a vital role. Too rigid, and creativity stifles; too loose, and chaos reigns.
The journey commences with a clear understanding of the data requirements aligned with the AI objectives. Organizations need specialists who not only understand the technical nuances but also grasp the business imperatives driving AI projects. The collaboration between diverse teams—data scientists, domain experts, and IT professionals—creates a fertile ground for innovative solutions.
Likewise, embedding quality assurance throughout the process enhances the outcomes. Regular reviews and feedback loops ensure deviations are addressed swiftly and accuracy is sustained. With technology continuously evolving, introducing adaptable methodologies ensures that the AI training data preparation process remains efficient and up to date. It’s a dynamic dance between technology and strategy, requiring finesse and foresight. When executed well, it positions organizations at the forefront of AI-driven innovation, echoing the harmonious results of a well-played symphony.
—
Analyzing the Intricacies of AI Training Data Preparation
Peeling back the layers of data preparation unveils its complexities and nuances. Often underestimated, the AI training data preparation process is pivotal in achieving optimal AI outcomes. In this narrative, understanding these intricacies is akin to mastering a new language—demanding both patience and expertise.
The process begins with embracing data diversity. In a recent interview with industry experts, it was noted that AI systems thrive on data variability. The broader the data spectrum, the better the AI understands context, much like how exposure to varied literature enhances language proficiency. However, with diversity comes the challenge of maintaining data uniformity—ensuring data is consistently structured and formatted becomes paramount.
Bridging the Data Preparation Knowledge Gap
Data preparation requires both technical know-how and domain expertise. The AI training data preparation process intertwines fields, demanding interdisciplinary collaboration. Bridging this knowledge gap involves creating knowledge exchanges where data scientists and domain experts share insights and align on objectives.
Harnessing Automation for Efficiency
Automation emerges as a key ally in managing data preparation. By delegating mundane tasks to automation tools, teams can focus on areas requiring human insight—conceptual understanding and strategic decision-making. These tools can parse through massive datasets, ensuring no stone is left unturned, albeit under human supervision.
Moreover, emotional intelligence plays a surprising role in data preparation. Understanding biases within data and ensuring fair representation emerges as a moral imperative. Data that reflects societal prejudices compromises the impartiality of AI systems. Hence, instilling empathy and fairness during the preparation stage contributes to a more ethical AI outcome.
At its core, the AI training data preparation process is a tapestry woven from threads of technology and humanity. It calls upon a diverse ensemble of skills and expertise, demanding both clinical precision and creative intuition. By mastering its intricacies, organizations can unlock AI’s transformative potential and harness it for monumental advancements across various sectors.
Assessing Current Data Practices
In evaluating current practices, many organizations are revisiting their data preparation strategies, especially in light of evolving AI applications. Combining traditional techniques with innovative approaches, they aim to refine their processes and align them with dynamic industry standards. Regular audits, training sessions, and strategic partnerships are just a few ways to stay ahead.
—
Effective Tips for AI Training Data Preparation
Optimizing the AI Training Data Preparation Process
In the world of artificial intelligence, data preparation is akin to a craftsman’s careful touch. Perfecting this process requires awareness and execution of nuanced practices. Imagine hosting a grand party, where every detail, from catering to entertainment, is meticulously orchestrated—similarly, if you’re looking to elevate AI outcomes, data preparation demands equal finesse.
By diversifying data sources, businesses build resilient AI systems with a rich tapestry of information. A study from McKinsey highlights that AI models trained on diverse data are more adaptive and generalized, yielding better predictions and insights. This diversity acts like a multivitamin, fortifying AI’s capacity to tackle complex scenarios.
Emphasizing data quality is non-negotiable. Imagine wearing mismatched socks to an important meeting—it leaves a discordant note! Data irregularities impact AI’s performance drastically. Through cleansing and validation, datasets emerge polished and ready for accurate model training. Automated solutions can relieve the burden of repetitive cleaning tasks, allowing human minds to focus on strategic oversight.
As AI continues reshaping industries, optimizing data preparation becomes vital. Companies navigating this landscape gain a substantial lead, transforming raw data into actionable insights with ease. Discovering these strategies is like finding a treasure map, guiding them through unknown territories towards breakthroughs and innovation.
—
Short Content on AI Training Data Preparation
Artificial Intelligence, the harbinger of the next industrial revolution, isn’t built in a day, nor is it built on poor data. The AI training data preparation process is the bedrock upon which resilient AI models are constructed. Think of it as tuning a guitar—without proper adjustment, the music produced will be off-pitch. Ensuring this process is robust directly translates into the effectiveness of AI systems.
Part of this preparation involves reining in the chaos of raw, unstructured data. It’s no secret that data is often messy, inconsistent, and riddled with gaps. Imagine hosting a dinner party with a scattered grocery list. That’s your data without preparation—all over the place! A systematic approach, complete with data cleaning, ensures everything is as polished as dinner table silverware.
Streamlining Data Practices
With the help of automation, many redundant data preparation tasks can be mitigated, allowing data scientists to invest time in tasks demanding critical thinking and strategic reasoning. Not only does it speed up the preparation process, but it also ensures consistency—a key ingredient in the AI recipe for success.
Avoiding Common Pitfalls
Yet, it’s vital to tread carefully, for the AI training data preparation process is riddled with potential pitfalls. These include biases in data, which can propagate through AI models if not addressed. By ensuring data is representative and unbiased, organizations sidestep these traps and safeguard the integrity of AI outputs.
Done right, the AI training data preparation process is akin to crafting a work of art—not only does it require technical finesse, but also a strategy that marries structure and spontaneity. Anticipating the needs of AI systems and priming them with enriched data forms the cornerstone of successful AI initiatives. Preparing data with agility and precision ultimately sets the stage for AI’s transformative symphony, resonating across industries with breakthrough innovations and competitive insights.