Hey there, fellow data enthusiasts! Today, we’re diving into the sometimes perplexing yet fascinating world of machine learning, specifically looking at the pesky problem of overfitting. It’s like trying to fit all your life’s experiences into a single suitcase—it’s bound to be a tight squeeze, with lots of things jutting out. But why does this happen in the case of algorithms? Let’s explore!
Why Do Algorithms Overfit?
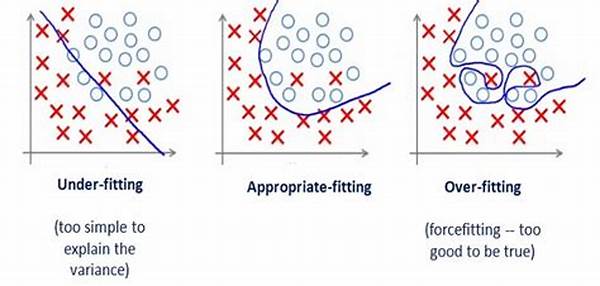
Alright, so let’s break it down as simply as possible. Overfitting occurs when an algorithm models the noise in the training data rather than the actual signal—the real patterns. Imagine being in a room full of chatty people; your goal is to understand the main conversation. If you try to understand every murmur and giggle, you’ll end up getting overwhelmed. That’s precisely what happens to some algorithms—they start capturing the noise alongside the core features of the data.
One of the primary causes of overfitting in algorithms is having an overly complex model. It’s like trying to catch a tiny fish with a mammoth-sized net; sure, you grab everything, but at what cost? The model might end up considering random quirks in the training data as significant, which are really just incidental noise.
Another factor? Not having enough data to train on. Imagine trying to write an epic novel with just a couple of sentences; not ideal, right? With limited data, algorithms can get stuck focusing too closely on the available examples. They desperately try to extract every bit of information they can, often resulting in overfitting. This tendency to misinterpret the random fluctuations as learned concepts is part of the core causes of overfitting in algorithms.
Common Culprits Behind Overfitting
1. Complex Models: Using a model that’s too sophisticated for the actual complexity of the data can lead to overfitting. It’s like using a chainsaw when a butter knife will do.
2. Insufficient Data: When data is scarce, algorithms have too little to learn from, often causing them to cling too closely to what they have—resulting in overfitting.
3. Noise in Data: Data riddled with errors or random fluctuations can mislead algorithms into thinking these are valuable patterns, misleadingly contributing to overfitting.
4. Lack of Regularization: Without constraints to keep a model in check, it can go wild learning from every tiny fluctuation, one of the key causes of overfitting in algorithms.
5. Overly Specific Input Features: Using too many specific features can make an algorithm too fine-tuned to the training set, instead of generalizable to new data.
Tackling Overfitting: A Deeper Dive
So, how do we keep our algorithms from getting overzealous with the details? One approach is regularization—a mathematical way to penalize overly complex models, nudging them to focus on simplicity. Think of it as telling your algorithm, “Hey, chill out and look at the big picture!” By imposing some restrictions, we prevent the model from going down the rabbit hole of complexity—a significant step in addressing the causes of overfitting in algorithms.
Cross-validation is another handy tool in the fight against overfitting. By splitting the data into diverse subsets, we ensure our model isn’t just learning the quirks of one isolated dataset. It’s like training for a marathon on different terrains rather than just the treadmill; your algorithm gets diversified exposure and learns to adapt better.
It’s also important to keep an eye on the quality of data. Garbage in, garbage out, as they say. Ensuring high-quality, noise-free data can significantly reduce the risk of overfitting. Like how a shiny new camera can capture clearer images, clean data helps algorithms focus on what’s important, separating the wheat from the chaff.
Exploring Causes of Overfitting: More Insights
Understanding the causes of overfitting in algorithms involves knowing the balance between bias and variance. A model with high variance learns too much from the training data—capturing its noise, leading to overfitting, while a balanced model can generalize well to new data scenarios.
Considering the features we input also plays a crucial role. More features might seem better, like upgrading to a fancy all-inclusive vacation package. But if those features are irrelevant, it knows too much and yet understands too little about meaningful patterns—one of the underlying causes of overfitting in algorithms.
Hyperparameter tuning is another area of importance. Tuning these parameters without care, akin to tinkering with each component of a recipe until it becomes overdone, can lead to performance issues including overfitting. Instead, we need to strategically adjust these parameters so they align with the model’s primary goal.
Drilling Down on Algorithm Overfitting
Alright, let’s dissect this a bit more. One of the focal causes of overfitting in algorithms is simply not having enough variety in training examples. Think about it; if an algorithm only sees one type of scenario, it questions its ability to handle new types. Diversity in training data is key.
Techniques like pruning and early stopping can be lifesavers. They help simplify the model by preemptively halting the training process or trimming branches in decision trees, respectively. Consider it like deciding not to go back for yet another serving at the buffet when you’re already full—avoiding unnecessary heaviness.
Model simplification works similarly by reducing layers or nodes in deep learning architectures when they aren’t needed. By focusing on refining the model to its essentials, you keep it spry and adaptive, avoiding the dreaded repercussions of overfitting.
Conclusion: Wrapping Up Causes of Overfitting
In essence, the causes of overfitting in algorithms often boil down to a mixture of overly complex models, limited datasets, and noisy data. But with strategies like regularization, cross-validation, and judicious feature selection, we can mitigate these risks, ensuring our algorithms perform admirably in the real world.
So, next time you’re working with algorithms, remember: an ear tuned too finely to every whisper may miss the central melody. By focusing on data quality, model complexity, and validation strategies, we aim to strike that elusive balance—a model both insightful and adaptable without being overwhelmed by the minutiae.