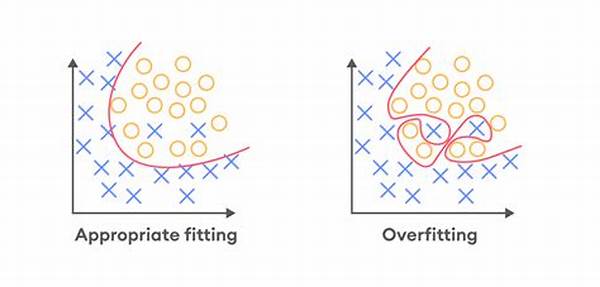
In the fascinating world of AI models, there lies a notorious villain known as overfitting. This sneaky foe threatens to derail your meticulously trained models, turning them into potentially unreliable predictors. But fear not, as understanding the complex challenges of overfitting issues in AI models could be the game-changer you need. Imagine putting in countless hours training an AI model, only to find it performing poorly when tasked with real-world data. It’s disheartening, right? That’s overfitting at its core—a situation where a model learns the training data too well, including its noise and outliers, and as a result, performs poorly on new, unseen data.
The implications of overfitting can be vast and could lead to economic losses in industries heavily reliant on AI, such as finance, healthcare, and autonomous driving. But therein lies the opportunity! By addressing these overfitting issues in AI models, businesses can ensure that their AI solutions are robust, versatile, and dependable. Understanding and mitigating overfitting is not just technical; it’s a business necessity. It’s a wonderful journey of fine-tuning your models so they don’t just mimic the training patterns but also generalize well to new situations.
Causes of Overfitting
One primary reason for overfitting issues in AI models is a complex model that learns every tiny detail of the training data, including noise. Imagine using a magnifying glass to study a landscape painting; you’re likely to notice each brush stroke, and that’s how a complex model behaves with data! Another culprit can be limited and poor-quality data. When a model doesn’t get enough diverse data points during training, it tends to latch onto whatever patterns it finds.
—
Understanding Overfitting in AI: Why it Happens and How to Solve It
When we think about the magic of AI—be it predicting stock prices, diagnosing diseases, or even creating art—we often overlook the hurdles that come with creating these sophisticated models. Overfitting is one such hurdle that any data scientist or machine learning engineer is likely to encounter. To get to grips with this, let’s delve into the causes, repercussions, and solutions for overfitting issues in AI models.
At its heart, overfitting occurs when a machine learning model captures not only the true underlying patterns in the data but also the random noise. This results in excellent performance on the training data but lackluster results on new, unseen data. Picture training a child to recognize cats by showing them only images of fluffy white kittens. The child might end up thinking that only fluffy white creatures are cats, ignoring the variety in the real world. This analogy illustrates the overfitting conundrum in AI models—where specificity on training data doesn’t translate to understanding the broader picture.
The repercussions of overfitting issues in AI models are palpable across various sectors. For instance, in financial forecasting, an overfit model might predict the past year’s stock movements with remarkable precision, promising hefty gains but faltering the moment it’s put to the test in real financial markets. It’s like having a GPS that can only lead you through your hometown but is utterly useless anywhere else. The economic and operational risks of deploying overfit models make understanding and resolving these issues critical.
One promising way to tackle overfitting is through regularization techniques. Regularization adds a penalty for complexity to the loss function, effectively trimming the model’s hypothesis space and nudging the model towards simpler solutions that generalize better. It’s like teaching the aforementioned child the general features of all cats rather than just focusing on fluffy feline examples. By doing so, the model learns the core concept without getting entangled in unnecessary complexity.
Cross-validation is another effective strategy. By dividing the data into training and validation sets, or even opting for k-fold cross-validation, we expose the model to more data variability, making it less likely to memorize the training set’s quirks. It allows the model to adapt to data diversity, akin to showing the child not just fluffy kittens, but also sleek Siamese or hefty Maine Coons.
The Role of Data Quality
A less discussed but equally significant aspect is the role of data quality in combating overfitting issues. High-quality, diverse datasets ensure that models learn a balanced representation, reducing over-reliance on insignificant data noise. It’s akin to exposing the child to a library of cat photographs from different sources, ensuring they grasp the essence of what makes a cat a cat, rather than picking up on misleading cues.
—
Discussions on Overfitting Issues in AI Models
Purpose of Addressing Overfitting in AI Models
The prime objective of understanding and resolving overfitting is to develop AI models that are not just accurate on training datasets but also adaptable to unforeseen challenges brought by new data. Imagine deploying an AI-driven healthcare screening tool. If it mistakenly classifies common symptoms as rare diseases because it was overfitted to the training set, the consequences could be grave.
Furthermore, addressing overfitting issues opens up a realm of opportunities for businesses. Companies equipped with AI models managing to generalize well can offer innovative products and services, confident in their AI’s analytical chops. In competitive markets, this reliability provides a unique selling proposition, fostering trust and expanding customer base. Thus, recognizing and addressing overfitting issues in AI models isn’t merely a technicality; it’s a strategic endeavor that aligns technological prowess with business acumen.
—
Effective Strategies to Combat Overfitting in AI Models
Description of Tackling Overfitting Issues
Overfitting, an all-too-common pitfall in machine learning, especially plagues AI models designed for real-world applications. Addressing this issue requires a multifaceted approach that carefully balances learning precision and generalization. Simplifying models by removing unnecessary features can reduce complexity, making models less prone to fit noise rather than genuine data trends.
Improving data quality is a cornerstone strategy. High-quality datasets, rich in variety and depth, allow models to have a broader understanding of the data landscape. Through data augmentation techniques, models can be exposed to slight variations in data, promoting resilience against overfitting. Furthermore, incorporating regularization methods like L1 and L2 helps control the magnitude of feature weights, driving the model towards generalization.
Lastly, employing techniques like early stopping and dropout introduces mechanisms that safeguard against overfitting during training. Early stopping halts the training process when the model’s performance on a validation set begins to deteriorate, while dropout randomly omits neurons during training, making the network less dependent on specific pathways. Together, these strategies forge a holistic defense against the ever-looming threat of overfitting, ensuring AI models are not only precise but also widely applicable.
—
Exploring the Depths of Overfitting in AI Models
In the electric world of AI, where predicting future trends feels almost magical, one must navigate carefully through the tricky pathways of model training. Here enters the subtle saboteur: overfitting. Overfitting issues in AI models are notorious for turning an awe-inspiring model into a predictable disappointment.
Why Overfitting Emerges
The emergence of overfitting can often be traced back to the model’s complexity. When an AI model becomes too finely tuned to the noise within its training data, it loses its ability to generalize. Imagine crafting an exquisite sculpture from sand—while impressive, a small gust of wind can render it unrecognizable. This captures the fragility seen in overfitted models when exposed to new data.
Network architecture also plays a significant role. Complex architectures with numerous parameters are like eager learners, excited to memorize every single detail, even those less relevant. This eagerness becomes counterproductive, leading to overfit models that struggle with new information.
Impact of Overfitting
Overfitting issues in AI models can yield severe repercussions. Within sectors like medicine or finance, deploying overfitted models might result in life-altering mistakes or financial disasters. Thus, detecting and mitigating overfitting becomes critical not only for operational success but also for ethical responsibility.
Solutions to Overfitting Challenges
Combating overfitting requires implementing strategic defenses such as cross-validation and regularization. Cross-validation tests model robustness on various data subsets, ensuring it adapts instead of memorizes. Regularization methods add a penalty for complexity during training, nudging the model to opt for simpler, more generalizable solutions.
Role of Diverse Datasets
A silver lining in the fight against overfitting is leveraging high-quality, diverse datasets. Datasets reflecting a wide range of scenarios ensure models don’t latch onto irrelevant features, enhancing their practicality in real-world applications.
Final Thoughts
The journey to overcoming overfitting issues in AI models underscores the delicate balance between model complexity and data quality. While intricacy and performance may seem attractive, simplicity and generalization hold key positions in crafting reliable AI solutions. In the end, the interplay of these factors shapes an effective, adaptive model ready to tackle future challenges.
Bridging the Gap
Understanding and addressing overfitting extends beyond producing accurate AI models; it’s a mastery of aligning AI capabilities with practical, real-world efficacy. It highlights the importance of building foundational AI solutions capable of transformative impacts, rooted in reliability and foresight.