In the intricate world of machine learning and data science, there lies a hidden gem that’s often overshadowed by the allure of complex models: feature selection. This crucial step in data preprocessing can make or break the performance of a model. But why does it matter so much? Well, imagine trying to navigate a crowded room blindfolded while someone whispers the right path. That’s your model without feature selection—overwhelmed with noise and distractions. On the other hand, a model utilizing effective feature selection methods is like having a clear roadmap, helping it to understand patterns better and generalize well on unseen data.
Feature selection methods aim to pick the best subset of input variables (or features) that are most relevant to the prediction task. The impact of feature selection methods is profound. It not only boosts model accuracy but drastically reduces computational time and prevents overfitting. This ensures that your model learns from the data rather than memorizing noise, making it more reliable and robust.
In the age of big data, where datasets can have thousands or even millions of features, the challenge is to distill the essence of the data efficiently. The impact of feature selection methods is akin to filtering gold from gravel. With the right process, the precious nuggets of information stand out, and the superfluous elements are discarded. Organizations are investing in effective feature selection approaches more than ever, as they realize that quality precedes quantity. Hence, understanding these methods is not just beneficial—it’s imperative for any aspiring data scientist or seasoned practitioner aiming for excellence in their domain.
Why the Impact of Feature Selection Methods is Game-Changing
Feature selection plays a pivotal role in simplifying models, improving accuracy, and enhancing the interpretability of machine learning systems. A streamlined, concise model isn’t just more manageable and consumes fewer resources; it also delivers results with a confidence that’s hard to achieve otherwise. Models equipped with fewer but more relevant features operate efficiently, offering quick responses in real-time applications. The impact of feature selection methods is the secret behind the blazing-fast algorithms that tech giants use to manage their colossal datasets.
Now, for a sprinkle of humor—imagine a donkey trying to carry every bit of cargo from a ship. That’s your data scientist overloaded with all raw data features. But feature selection is like switching that donkey for a sleek sports car, taking only what’s essential for the journey ahead. It’s faster, slicker, and undoubtedly cooler. No wonder more enterprises are riding the feature selection wave, treating it as a critical investment for the future. By prioritizing what’s genuinely important, they’re setting new heights in data-driven decision making, marking the undeniable impact of feature selection methods on their successes.
—
The Foundation of the Impact of Feature Selection Methods
Feature selection is arguably one of the most significant steps in the machine learning pipeline. Serving as a foundation, it influences the efficiency, speed, and success of models. The impact of feature selection methods extends beyond just clear outputs; it crafts the backbone for scalable and interpretable systems. For those new to the world of data science, feature selection might sound like a fancy term, but its power is transformative.
Feature selection achieves a fine balance between bias and variance, reducing dimensionality while preserving informative elements. This balance is essential, as models with too many features might become too complex and overfit, while too few might underfit. The impact of feature selection methods is the answer to finding that sweet spot where models perform optimally regardless of the data spectrum.
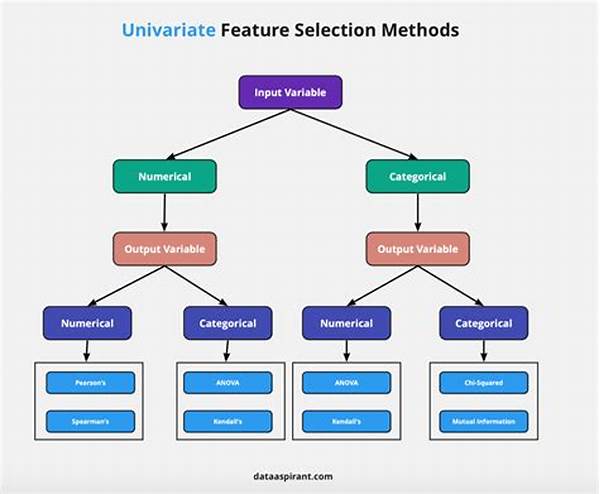
While various techniques exist, from filter methods to wrapper methods and embedded methods, each carries its own pros and cons. The choice often depends on the dataset size, problem type, and computational resources available. Ultimately, the aim is to unveil the hidden gems within the data.
Wrappers, Filters, and Their Impacts
These methods revolutionize how features are selected. Filters evaluate the relevance of features through a statistical relationship with the output variable, operating swiftly at the expense of ignoring possible interactions between features. On the other hand, wrappers take it a notch higher by considering the predictive power of a set of features; however, they’re often computationally intensive. Despite their differences, both play a crucial role in showcasing the impact of feature selection methods.
Educative Insight on Embedded Methods
When it comes to embedded methods, these crafty techniques integrate the model-building process with feature selection. Algorithms like LASSO, Ridge, and Decision Trees inherently select features by imposing penalties on the model. Their popularity is rising because they strike an effective balance between automatic feature selection and classification accuracy.
The stance today is clear—without feature selection, raw data is just that: raw. But with the right selection method, data transforms into a refined, insightful tool that can drive major decisions. Thus, the impact of feature selection methods is not just critical; it is revolutionary for the future of data-driven strategies.
—
Real-Life Examples of the Impact of Feature Selection Methods
Feature selection is not only theoretical—its power is prevalent in various real-life applications. This section explores several compelling examples.
The impact of feature selection methods cannot be overstated. In every strategic domain, its pivotal role defines success stories, highlighting efficiency and precision as the essence of modern data science pursuits.
—
Exploring the Scope: Impact of Feature Selection Methods
The marvel of feature selection is in its ability to cope with diverse data below the surface level intricacy. Here, we dive into some short explanations:
With these insights, it is evident that the impact of feature selection methods goes beyond the superficial, revealing a landscape of opportunities for optimized model performance and strategic data triumphs.
—
Impactful content like this shines a light on the immense possibilities with feature selection. Whether through testimonials from industry professionals or success stories from businesses adopting these methods, the narrative is clear: embracing the impact of feature selection methods unlocks futures brimming with potential.