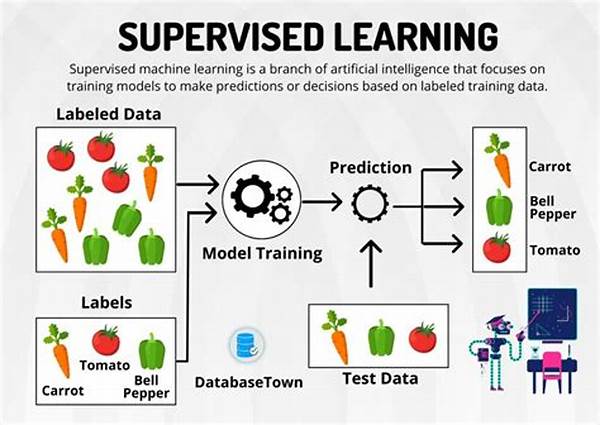
H1: Training Sets for Supervised Models
In the dazzling world of data-driven decisions, where algorithms command the stage, training sets for supervised models play the lead role. Imagine these data sets as nourishing soil, essential for sprouting the seeds of machine learning models that power everything from your smartphone’s face recognition to the recommendations popping up on your streaming service. Without them, the fulfillment of these algorithms’ promises would be nothing more than a mirage.
To embark on this data journey, let’s set the scene: picture an artist’s palette. With each stroke of data point, the broader picture of a model begins to form. The training sets for supervised models are much like this palette, providing both source and substance. Just like each color serves a unique purpose and blends to create masterpieces, each data point contributes to the fine-tuning of a model’s predictions. But caution: possess your palette wisely, lest your masterpiece turns monochrome and dull.
Understanding training sets for supervised models is akin to learning a musical instrument. Picture yourself at a grand piano, with every key representing unique data points. Essentially, you become the maestro as you orchestrate the harmony and melody of different data types to teach the model to decipher notes and compose symphonies of predictions. A slight misinterpretation, however, and even the most promising notes might sour into dissonance. Herein lies the intrigue—using data to pull on both your left brain’s rational strings and your right brain’s creative chords, all to concoct predictive marvels.
H2: The Art and Science of Data Selection
Choosing the right training sets for supervised models is a delicate art intertwined with precise science. Selecting optimal data to train your model involves not merely volume but also diversity and relevance. Think of it as baking perfect cookies; you don’t just need flour and sugar but the right kind of chocolate chips, just the right amount of heat—even a dash of creativity. Similarly, a balanced training set results in a model that’s both robust and delectable, ready to tackle real-world problems with agility and poise.
—
When considering machine learning, each model’s acumen is sculpted by its training sets for supervised models. Just picture building a skyscraper—the blueprint may be impeccable, but without the right bricks and mortar, it stands just as tall as ambition without action. A superior model begins with superbly crafted training data, grounded in relevance and variety.
Selecting a compelling training set requires a discerning eye. Not every data point is born equal. In the bustling bazaar of big data, the discerning marketer sifts signal from noise, ensuring quality reigns over quantity. This process is much like a director casting for pivotal roles—each choice directly influences the narrative arc of the final piece.
Testing this curated set is pivotal. While it’s tempting to rest on laurels, iterating on data ensures the resonance of the model’s eventual application. This can be humorously compared to that persistent friend who won’t stop tweaking their chili recipe—each version spicier, bolder, and refined to delight. Yet, in the realm of machine learning, this persistence ensures robustness, not mere culinary satisfaction.
H2: Testing and Evaluation in Supervised Learning
Testing your training sets for supervised models is akin to rehearsing before the grand premiere—it prepares your models for execution in the unpredictable world stage. The iterative testing grounds solidify strengths and shine a spotlight on weaknesses, fostering a culture of continuous improvement. When models perform exceptionally on test data, it’s not merely about success—it’s a testament to the rigorous journey of creation and refinement.
—
Here’s a fascinating discussion starter on the topic of training sets for supervised models:
Let’s delve into the labyrinth of training sets for supervised models, where data not only tells a story but crafts destinies. To fully unleash the potential of these models, one needs not just data, but intelligent, impactful data. Ever watched a tightrope walker mid-performance? Precision, balance, and foresight guide their every move. Building training sets for supervised models requires similar prowess. Here, creativity meets analytical thinking in ways that render automation absolutely fascinating.
From the inception of a raw idea to the execution of a flawless model, the journey is layered with insights. It’s like being a chef in a bustling kitchen, where varied ingredients meld into culinary brilliance. Formulating an efficacious training set is equally engaging, demanding foresight to anticipate needs while retaining flexibility to adapt to unexpected tastes.
H2: Evolution of Training Sets
Over time, the dynamics of constructing training sets for supervised models have evolved, embracing novel methodologies and technological advancements. This evolution is akin to the transition from silent films to talkies in the movie industry—a marked enhancement in storytelling prowess. As models grow more complex, the integration of unconventional data solves problems once perceived as insurmountable, continually reshaping the landscape of AI-driven decisions.
H3: Beyond Traditional Data Collection
In conclusion, as with any evolving field, the key to understanding is engagement and curiosity. Always ask questions, seek diverse perspectives, and stay adaptable as new technologies emerge. Happy model training!