In the realm of machine learning, there’s an elusive balance between creating a model that perfectly captures the patterns in your data and avoiding one that overgeneralizes those patterns. When a model is too closely tailored to the training data, it loses the ability to perform well on unseen data, falling victim to the dreaded specter of overfitting. Imagine it as an overzealous student who has memorized the textbook cover-to-cover but struggles to apply concepts in real-world scenarios. Cross-validation comes to the rescue like a vigilant tutor, ensuring that our model learns to generalize and not merely memorize. This technique slices up our data into multiple partitions, rigorously training and testing the model, ultimately providing a more robust understanding of its performance capabilities across different data samples.
Cross-validation to prevent overfitting is essential, especially as datasets grow larger and more complex. With cross-validation, we essentially take our dataset on a series of mini test drives, each on a new and unexpected route. This adventurous journey through the data forces our model to not only excel on the paths it knows well but also to perform adequately on roads less traveled. This practice builds a model that’s not just book-smart but street-smart too.
The magic of cross-validation lies in its versatility. Whether you’re dealing with a linear regression model or a deep neural network, cross-validation helps you strike that delicate balance between bias and variance. It’s a tool that arms data scientists with the knowledge that their model isn’t just a top performer under favorable conditions but can hold its ground when the going gets tough. Now that we’ve captured your interest, let’s delve deep into the mechanics of cross-validation and how it helps in preventing the dreaded overfitting.
How Cross-Validation Works
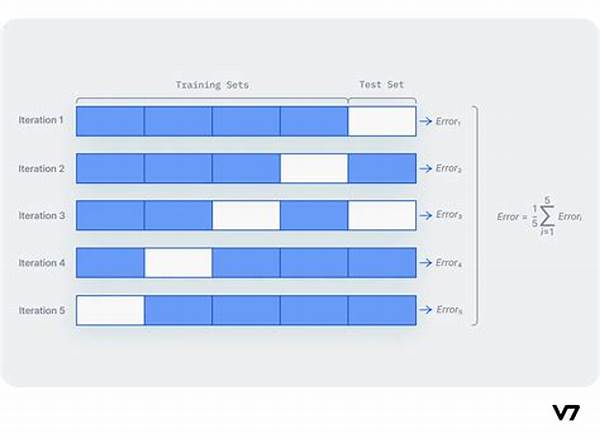
When it comes to preventing overfitting, cross-validation serves as a knight in shining armor. But how does this gallant process work behind the scenes? At its core, cross-validation divides your data into subsets, also known as folds. One fold is used for testing, while the remaining serve as training sets. This process is repeated across each fold, ensuring that every data point gets its time to shine in the testing role. This way, the model is trained and validated multiple times, each time producing a more generalized performance estimate.
Cross-validation to prevent overfitting relies heavily on its methodology. The most popular variant is k-fold cross-validation, where the data is divided into k distinct folds. Each fold acts as the testing set exactly once, while the remainder forms the training set. This iterative process yields k performance estimates, which are then averaged to provide a holistic measure of the model’s performance.
Types of Cross-Validation
Choosing the appropriate type of cross-validation can significantly impact the protection against overfitting. Apart from k-fold, there are several adaptations such as stratified k-fold, which ensures each fold has a consistent distribution of the target variable, leading to balanced partitions. Then there’s leave-one-out cross-validation, a more exhaustive and computationally intensive method where k equals the total number of data points, offering a granular assessment of model performance.
Cross-validation to prevent overfitting is not just a preventive measure; it’s an essential practice for any serious data scientist. By embracing this technique, you open the doors to building models that are both reliable and robust, capable of performing under the intricacies and surprises of real-world data.
Seven Topics Related to Cross-Validation to Prevent Overfitting
Purpose of Cross-Validation to Prevent Overfitting
Cross-validation to prevent overfitting is the Swiss army knife of data science, wielding the power to simultaneously test and refine models. Its core purpose is simple: to provide a realistic estimate of model performance that is free from the bias inherent in training data. This foresight allows data scientists to build models that not only excel in theory but also prove formidable against the unpredictability of new data. By rotating the role of test data among various subsets, cross-validation aspires to expose the weaknesses of a model early, long before it faces real-world application.
Moreover, cross-validation equips data scientists with the capability to make informed choices around model selection and hyperparameter tuning. It’s akin to trying on different hats before deciding which one fits best, minimizing the risk of committing to a model prematurely. Cross-validation empowers this decision-making process, guiding the choice toward models that can maintain performance consistency even when confronted with previously unseen data.
It’s fascinating how cross-validation lends itself to multiple phases of model development. From assessing initial model performance to fine-tuning final iterations, it ensures a comprehensive evaluation framework that leaves little room for the surprises of overfitting. The technique acts as an iterative reality check, constantly challenging assumptions and providing a narrative of a model’s deployment readiness.
In the dynamic landscape of machine learning, cross-validation emerges not just as a best practice, but as a critical prerequisite for building models that are robust, reliable, and ready for the real world. Armed with an effective cross-validation strategy, data scientists anchor their models in reality, reducing the risk of overfitting and enhancing generalization capability. Cross-validation to prevent overfitting isn’t just a technical process; it plays a pivotal role in crafting success stories in the narrative of data science.
Tips to Master Cross-Validation to Prevent Overfitting
Importance of Cross-Validation Techniques
Cross-validation techniques are indispensable tools in the data scientist’s repertoire, harmonizing the balance between model comprehension and real-world application. They offer clarity amidst the chaos of data, anchoring model training in a framework that strives for perfection without compromising adaptability. In considering cross-validation to prevent overfitting, it’s evident that these techniques do much more than just assess—they assure, ameliorate, and advance the entire modeling process.
From the precision of leave-one-out to the robustness of stratified k-fold, cross-validation tailors itself to the specifics of the data and the intricacies of the task at hand. This adaptability underscores its importance, promoting not just accurate but also equitable model behavior. It challenges the data scientist to continuously critique and iterate, yielding models that are resilient across datasets and circumstances.
As we continue our journey into the depths of model training, the stories of triumph over overfitting, told through cross-validation techniques, inspire both new and seasoned data enthusiasts. Whether it’s the saga of an outperforming algorithm that finally got its time to shine or the narrative of a rejected model that needed just one more iteration to make the grade, cross-validation makes sure every model’s potential is fairly appraised. In a rapidly evolving field, it is cross-validation that consistently delivers the insights necessary to make data-driven decisions truly reliable and revolutionary.