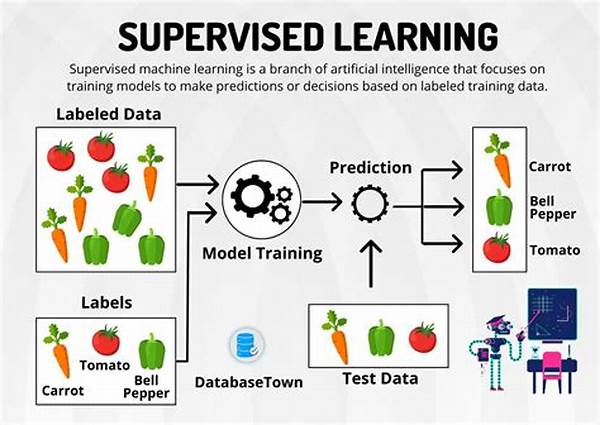
Data labeling in supervised learning stands at the heart of advancing artificial intelligence and machine learning technologies. Imagine teaching a child to differentiate between cats and dogs. You’d likely start by showing them pictures, pointing out key features, and repeating the labels. Similarly, data labeling is about identifying raw data, such as images or text files, and adding informative labels or tags to enable machine learning models to understand the desired outputs or patterns.
In the vibrant world of supervised learning, data labeling plays a pivotal role. It acts as the guiding star, directing algorithms towards understanding and interpretation. Like the unsung hero in blockbuster films, data labeling does not always get the spotlight, but its role is indispensable. The labeled data serves as a training set for supervised learning algorithms, allowing them to learn from examples and make predictions or decisions based on new, unlabeled data. Whether it’s the spam detection in your email inbox or the speech recognition on your smartphone, data labeling powers these everyday tech features. The journey might sound simple, but the process is intricate, demanding precision, attention to detail, and an understanding of algorithmic needs.
Despite its critical importance, data labeling in supervised learning can often resemble a Herculean task. The size and complexity of modern datasets mean there is an enormous amount of data to be labeled, a task that can be both time-consuming and prone to human error. However, innovative solutions and advancements, like automation tools and artificial intelligence, are providing some relief, streamlining operations, and enhancing the accuracy of labeled data. Yet, effective data labeling remains a crucial determinant of the success of supervised learning models. As tech titans and burgeoning startups continue their quest for a better tomorrow, data labeling will continue to evolve, propelling machine learning towards uncharted territories.
The Challenges and Solutions in Data Labeling
Data labeling sounds like a never-ending tale of challenges and triumphs. Although the process is labor-intensive, solutions lie in crowdsourcing, active learning, and automation. Crowdsourcing involves distributing labeling tasks across several individuals, thereby managing vast datasets efficiently. Meanwhile, active learning targets data that is most uncertain, improving label efficiency. Harnessing the power of automation, companies can use AI to pre-label data, subsequently refined by human annotators. This blend of human intelligence and technology not only accelerates the process but also increases precision, revolutionizing the world of data labeling in supervised learning.
—
In the world of artificial intelligence, embarking upon the adventure of machine learning is akin to exploring the vast realms of unknown galaxies. Supervised learning, a popular machine learning technique, implements a foundational concept that echoes how humans learn. We learn by observation, repetition, and feedback. In this domain, data labeling in supervised learning becomes paramount as it provides the significant feedback loop that transforms mere data into insightful knowledge. The narrative of supervised learning is incomplete without delving into data labeling, a critical phase where AI begins to make sense of data and finds its true potential.
The Essence of Labeling for AI
What makes data labeling in supervised learning a cornerstone of AI development? It’s the same reason you don’t bake a cake without following a recipe. In supervised learning, algorithms require ‘recipes’ or labeled data to interpret and learn patterns and relationships, similar to how we relate sounds with meanings in language learning. Data labeling is the bridge that connects theoretical AI capabilities with real-world applicability. It renders abstraction tangible, enabling algorithms to perform specific tasks effectively, from recognizing spoken words to detecting objects in images.
Breaking Down the Myth
There is a myth that AI works like magic – you feed in data, and voila, results! The magic, however, lies in meticulously labeled datasets. Data labeling in supervised learning dispels this myth, revealing a methodical process driven by meticulous work. With a focus on clarity, consistency, and accuracy, labeled data transforms the elusive magic into predictable outcomes. It opens the gateway to accuracy in machine learning applications, allowing AI to achieve remarkable feats in precision and reliability.
Though it might seem laborious, data labeling in supervised learning provides a framework to which all algorithms owe their prowess. Annotating datasets means we are not only labeling data but crafting the future of AI. Companies and developers invest in data labeling not just to create proficient algorithms but to steer the AI revolution towards more accountable and intelligent technologies. As we stand at the dawn of a technological era fluid with innovations, the demand for precise data labeling speaks volumes about its significance and ongoing development.
Why Is Data Labeling Indispensable?
In the grand scheme of training a machine learning model, data labeling serves as an essential element. Envision a novice chef learning to cook a complex dish; guidance and labeled ingredients are crucial to achieving anything edible. In parallel, data labeling in supervised learning provides the essentials that algorithms rely on to ‘learn’ and ‘cook’ accurate predictions. Without these critical labels, machine learning models would drift aimlessly, producing inaccurate outcomes.
For companies eager to push the frontiers of AI, investing in data labeling isn’t an option—it’s survival. By prioritizing data quality over quantity, businesses can ensure their AI models yield expected results while maintaining competitiveness in a rapidly evolving market. It’s an investment in precision, accuracy, and, ultimately, a more sophisticated AI ecosystem that continuously strives towards new heights.
—
Objectives of Data Labeling in Supervised Learning
—
Data labeling in supervised learning is not just about tedious markups—it’s an evolving discipline that dictates the efficiency of machine learning algorithms. The intrinsic challenges include maintaining label quality, consistency across annotations, and handling vast volumes of data. The balance between automated and manual labeling continues to be a priority as AI models rely heavily on the input they learn from. The human touch remains irreplaceable for nuanced judgment, while automation expedites the labeling process, creating a blend of technology and human precision.
For a company diving into AI, understanding the intricacies of data labeling in supervised learning is essential. It’s not just a backend process but a strategic pillar that defines AI success. It’s akin to an artist choosing the right colors for a masterpiece; the right balance between automation, human judgment, and continuous feedback loops shapes the effectiveness of AI applications. By acknowledging its challenges and integrating innovative solutions, enterprises can foster a landscape where AI thrives, producing reliable, intelligent, and ethically responsible outcomes.
—
Techniques for Effective Data Labeling
In exploring the journeys of data labeling in supervised learning, the path is fraught with choices. Choosing the right techniques determines the line between ordinary and extraordinary outcomes. Employing crowdsourcing allows for distributing tasks in handling vast datasets, whereas active learning optimizes label efficiency by focusing on uncertain data. Alongside, utilizing pre-labeling automation significantly reduces manual effort, enabling annotators to refine and perfect.
Human vs. Machine: Crafting a Symbiosis
While AI progresses each day, it is pivotal to remember that the symbiotic relationship between human intelligence and machine efficiency drives data labeling. Seamlessly integrating automated suggestions with expert human oversight not only optimizes results but crafts tomorrow’s intelligent frameworks. We stand on the brink of an AI revolution that hinges on our proficiency in data labeling.
By deploying these sophisticated techniques, companies reinforce their commitment to excellence, steering AI algorithms toward breakthroughs and transformative innovations. This deliberate investment in data labeling skillfully crafts AI’s roadmap, where precise data lays the foundation for tomorrow’s intelligent solutions.