Enhancing Model Accuracy with Cross-Validation
In the rapidly evolving world of machine learning and data science, achieving high model accuracy is not just a goal; it is an imperative. Enhancing model accuracy with cross-validation has emerged as a game-changing strategy that data scientists and analysts are leveraging to push the boundaries of predictive performance. So, what is cross-validation, and why is it making waves in the realm of model accuracy? Let’s journey through the landscape of enhancing model accuracy with cross-validation with an engaging narrative.
Cross-validation is a statistical technique that involves partitioning data into subsets where training is performed on one subset, and validation is performed on another. This robust approach allows for the assessment and fine-tuning of the model’s accuracy without overfitting or underfitting. It’s like the ultimate stress test for your model, ensuring that it performs well across different data scenarios. Consequently, enhancing model accuracy with cross-validation is not merely about diligent mathematical exercises but about unleashing the full potential of your data models.
Implementing cross-validation in model training ensures a more sustainable and reliable performance. Gone are the days when data scientists had to cross their fingers and hope their model would perform as expected when exposed to unseen data. With cross-validation, you can verify and validate your model’s performance during the initial development stages, significantly boosting your confidence in the results. It’s akin to a dress rehearsal before the grand performance, ensuring everything is perfected before facing the audience.
Models that can generalize well to unseen data are the zenith of machine learning success. Enhancing model accuracy with cross-validation plays a pivotal role in achieving this by providing insight into how a model behaves under various data configurations. Ultimately, this leads to better decision-making and more robust predictions. Cross-validation empowers data experts with a practical mechanism to refine their model’s capabilities before deploying them in real-world applications, be it in healthcare, finance, or any other sector reliant on data-driven predictions.
The Magic Behind Enhancing Model Accuracy with Cross-Validation
Cross-validation is magical in its simplicity yet profound in its application. By rotating the available data through training and validation phases, it offers a comprehensive view of how the model is performing. This method serves as a guardian against misleading assessments that could occur if only a single split of data was used. It is not merely about finding loopholes in data modeling but rather exploiting them to ensure models are battle-ready against various data intricacies. Thus, by highlighting potential pitfalls through rigorous testing, enhancing model accuracy with cross-validation becomes a viable strategy for achieving result-driven models with high reliability.
—
The Purpose of Enhancing Model Accuracy with Cross-Validation
Researchers and data scientists today leverage cross-validation to maximize model performance, ensuring that data models are not only precise but also consistently reliable. The essence of enhancing model accuracy with cross-validation isn’t just in the figures of accuracy scores but in ensuring the longevity and applicability of model predictions across different datasets. This technique serves multiple purposes, each contributing uniquely to improving model reliability and performance.
One primary purpose of cross-validation is to minimize overfitting. Overfitting occurs when a model learns not only the underlying patterns but also the noise within the training data. By testing the model’s performance across different subsets of data, cross-validation ensures that the insights learned are generalizable—that is, applicable to new and unseen situations. Enhancing model accuracy with cross-validation thus guards against producing over-optimized models that fail in practical applications.
Additionally, cross-validation equips data practitioners with deeper understanding and control over their models. With repeated trials and error checking, data scientists can better understand where their models may falter and why. Such insights can guide the precise calibration of model parameters, making models robust and adaptable. Hence, the purpose of enhancing model accuracy with cross-validation extends from mere accuracy to predictive wisdom.
Detailed Process in Enhancing Model Accuracy
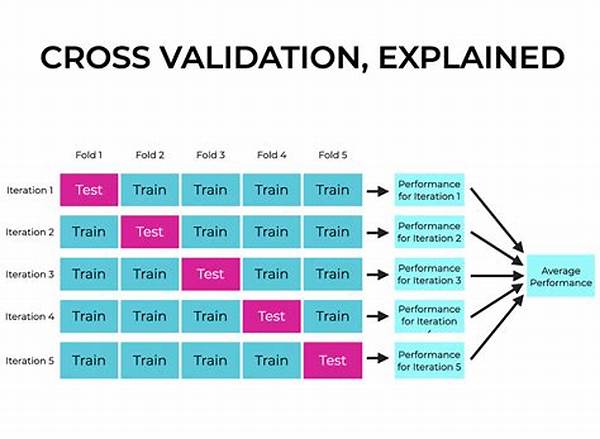
Cross-validation involves dividing your dataset into ‘k’ folds or parts, where each fold is used as a testing set at some particular stage. The model is trained on the k-1 remaining folds and later tested on the left-out fold. This process is repeated k times, allowing each fold to be utilized as a testing set once. The outcomes are averaged to provide a final accuracy estimate.
Benefits of Cross-Validation
The method yields many benefits, among which is the reduction of bias. Each data point gets to be in a testing set once and is utilized in training k-1 times, enhancing the dependability of the model’s outcome. Investigations show that cross-validation offers balanced accuracy metrics, avoiding pitfalls linked with random train-test splits.
Moreover, cross-validation aids in the evaluation of model variation, equipping data specialists to fine-tune their models efficiently. By reviewing results from various train-test splits, one can better comprehend how their model performs under different data scenarios. The goal is to confirm their models’ ability to deal with real-world data scenarios they are expected to encounter upon deployment.
Ultimately, cross-validation becomes an educational journey, shedding light on a model’s weaknesses and strengths alike. Its detailed process provides a pathway towards enhancing model accuracy with cross-validation, where efficiency meets reliability.
—
Goals of Enhancing Model Accuracy with Cross-Validation
Understanding the Journey
Enhancing model accuracy with cross-validation is not just about hitting higher accuracy scores—it’s about the journey of understanding and refining data models to perfection. The rigorous testing through k-folds teaches valuable lessons in persistence and innovation. Each attempt at refining the model uncovers new insights, bridging the gap between theoretical potential and practical application.
The learning engagements in cross-validation foster a kind of detective work, uncovering the secrets that lie hidden within large and complex datasets. Here, models are put through a series of hoops, each one representing a real-world challenge they might face. This journey is transformative, where the models are equipped with not only the means to predict but also to understand.
As the story unfolds, the models’ journey through the rigors of cross-validation leaves them stronger and more equipped. Those who harness this technique find their models are no longer static but growing, adjusting, and evolving alongside the data they interpret. Ultimately, enhancing model accuracy with cross-validation transforms raw data into wisdom, honing models that not only predict but enlighten.
Path to Mastery
The challenge and allure of enhancing model accuracy with cross-validation lie in its capacity to develop models that are both intelligent and intuitive. Cross-validation serves as the crucible in which models are tested, forged, and refined, producing outcomes that echo the complexity and beauty of the data they seek to decipher.
This approach is a masterstroke in data science, breathing life into numbers and rendering them into insightful narratives. It encourages practitioners to not only seek results but to understand the whys and hows of achieving them. For those on this quest, the path to mastery in enhancing model accuracy with cross-validation is as much about discovery as it is about achievement.
—
How to Improve with Cross-Validation: Practical Tips
Charting the Success Path
To enhance model accuracy with cross-validation successfully, understanding and implementing these tips is crucial. Better results are not just about changes in model architecture but also involve measures in how cross-validation itself is wielded. The harrowing tales of data endeavors often end with triumph through these practical tips.
Through refined techniques, enhanced insights emerge, illuminating paths not previously considered. Stories of success with cross-validation do not stem from luck but from calculated methodologies and persistent refinement. The journey of improvement is the journey of innovative breakthroughs where refinement meets opportunity.
This exploration not only sets a new standard for model testing but also reshapes how we view data challenges. The narrative changes from a series of statistics to a story of triumph, crafted through the dedication to enhancing model accuracy with cross-validation. The road to better accuracy is paved with strategic insights and actionable techniques, promising a landscape of possibilities.
The stories shared within this domain are that of perseverance and expertise. Enhancing model accuracy with cross-validation signifies more than an adjustment in methodology—it represents a transformation in understanding and interpreting the data science world. Through its lens, the path to success in data modeling is clearer and more attainable.
—
By understanding and implementing these methodologies, enhancing model accuracy with cross-validation becomes not just a possibility but a certainty. It is a testament to the potential that lies within data science and the transformative power of thorough testing and understanding. As cross-validation continues to redefine the art and science of data modeling, the stories of triumph and enlightenment it fosters will never cease to inspire those bold enough to explore them.