In the thrilling world of machine learning, there’s an ongoing quest to design models that not only fit our training data but also perform well on unseen data. This elusive skill of a model to extend its learnings to new and unseen data is what we call generalization. The art of model generalization is quintessential for building robust machine learning applications. Imagine building a model that’s quirky and fun, akin to a detective unraveling mysteries, as it probes into vast datasets to find patterns that others might miss. However, a model’s journey to generalization nirvana isn’t straightforward. It demands a diligent methodology, and that’s where cross-validation techniques make their grand entrance!
Cross-validation methods, particularly in their role within model generalization, operate like a maestro fine-tuning an orchestra, ensuring every note – or rather, data point – plays in perfect harmony. Picture a setting where a machine learning model is put through rigorous rounds of scrutiny – folding, shuffling, and partitioning of data – all in an attempt to master its craft. Through this continuous cycle, the model becomes increasingly adept at understanding the depths of validation, etching its name in the hall of fame of precision and accuracy.
In a domain where accuracy is the currency and precision the badge of honor, understanding and implementing model generalization using cross-validation methods becomes not just a requisite but an obligation for every data scientist. This journey is packed with the thrill of exploration, the challenges of fine-tuning, and the joy of witnessing a model that not only learns but ‘understands’. Shall we dive deeper into this captivating tale of model-generalization mastery?
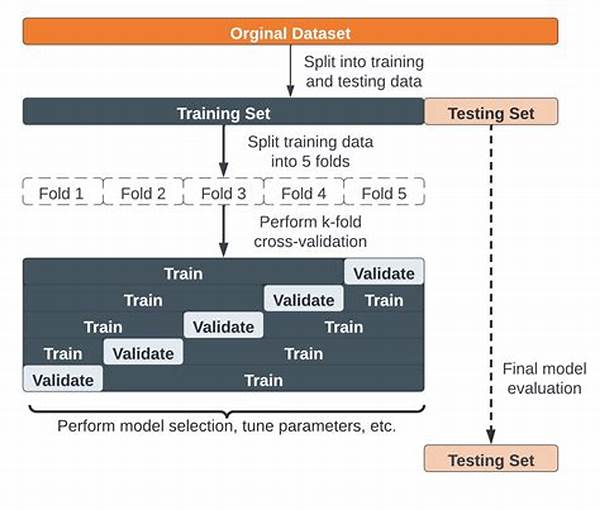
To kick off, cross-validation is an absolute game-changer. Imagine dividing a dataset into several bits, called folds, to independently validate portions. This method helps detect overfitting, ensuring our model doesn’t just memorize but truly learns. Notably, ‘k-fold cross-validation’ takes center stage where data is split into ‘k’ number of folds or parts. Here’s where magic happens: each fold gets a turn in the spotlight to act as testing data while the rest train the model. This round-robin style ensures that every part of our data has a role to play in creating a champion model.
The Intricacies of Cross-Validation
Exploring the corridors of cross-validation, belt in for a journey filled with numerical insights and data wisdom. Each type of cross-validation method unveils its unique charm. The holdout method, simple yet compelling, brings a sense of basic simplicity that can be seductive for smaller datasets. On the other hand, the stratified variant of k-fold steals the limelight when dealing with classification problems, ensuring each fold is a true representation of the entire data universe.
For the adrenaline seekers of the machine learning world, nested cross-validation offers an extra layer of excitement. With model selection meshed into the process, this approach combats selection bias, ensuring our chosen model isn’t just good—it’s the best. You see, the dance of model generalization using cross-validation methods isn’t just an experiment; it’s a strategy for forging ahead into the frontiers of innovation.
Finally, let’s address the question on everyone’s lips: “How does one utilize this method in real-time projects?” Quite simply, integrating model generalization using cross-validation methods means winning over confidence in your model’s predictive power. This isn’t merely academic; it’s strategic application ready to be deployed in real-world scenarios, bringing data to life with its predictive prowess.
—
Discussion on Model Generalization Using Cross-Validation Methods
Carrying on from where we began, the clamor around model generalization using cross-validation methods serves as a beacon for the uncharted territories of predictive proficiency. Why do these methods hold such esteem in the data science community? It’s because they provide a crystal ball glimpse into the future performance of our machine learning models without succumbing to prediction biases.
Cross-validation’s prowess lies in its versatility in addressing dataset nuances. Whether you’re a budding enthusiast experimenting with your first dataset or a seasoned data wrangler seeking to annihilate biases, choosing the right cross-validation technique can radically improve model accuracy. These validation methods create an ensemble of models, each refining its learning journey from the mistakes of the others. Such synergy often results in a model that stands against the test of time and data variability.
Consider a scenario where your model’s prediction prowess faces a daunting challenge: unbalanced classes within a dataset. The intelligent deployment of stratified k-fold cross-validation would ensure equal representation of different classes within your testing sets, offering results that are both balanced and reliable. This nuanced application paves the path for models that mirror real-world complexities with commendable precision.
Equally, there’s a narrative involving nested cross-validation—a gallant adventurer battling parametric monsters. Within its architecture lies a dual-loop structure, combating overfitting in model selection while ensuring optimized parameter settings aren’t just a fluke. The result? Models ready to face any predictive challenge with an armor of accuracy and shield of reliability.
Understanding Nuanced Applications
As these methods are deployed across varied scenarios, their value magnifies. Think of scenarios ranging from medical imaging, where the stakes are incredibly high, to financial predictions where every decimal point matters. Realizing the critical need for robust models that generalize well can be likened to armory in a battlefield—ever-aiding, ever-ready.
But while cross-validation methods are mighty, they aren’t absolute rulers. They require computing resources, careful handling of data partitioning, and an understanding of the data structure to unfold their potential truly. Inadvertent missteps can lead to prolonged computation times or, worse, overfitting and bias—turning even the most promising datasets into cautionary tales of underperformance.
Strategies for Effective Usage
To mitigate these concerns, strategic integration becomes the linchpin. Recognizing when to employ k-fold versus its stratified variant, or opting for leave-one-out cross-validation can provide not only efficiency but also precision. These aren’t decisions made in isolation; they require practitioner insight, project context, and systemic understanding of data behavior.
Implementation doesn’t just end with cross-validation methodologies; it extends to model evaluations and adjustments, ensuring that our journey doesn’t just culminate with theoretical efficacy but translates into actionable insights and dependable predictions. Usher in an era where your models not only adapt but thrive in the realities of the unpredictable data landscape.
—
Examples of Model Generalization Using Cross-Validation Methods:
Delving into the art of cross-validation unfolds like an engaging tale. In this enlightening narrative, model generalization using cross-validation methods continually surprises with its balance of innovative theory and empirical truth. As data scientists venture deeper into the data cosmos, the adoption and mastery of these validation methods hold the promise of transforming datasets into valuable predictive powerhouses.
The Power of Cross-Validation Techniques
With models that refuse to yield under the pressure of new data, the application of these advanced validation methodologies secures the future of reliable, efficient, and adaptable systems. Are you prepared to step into this realm and etch your mark in the annals of machine learning excellence?
—
Exploring Further and the Path Forward
A key takeaway for practitioners is recognizing that model generalization using cross-validation methods is not just a theoretical stance but a practical directive that can shape the success narratives of machine learning projects. The synthesis of data analytical skills, cutting-edge cross-validation techniques, and real-world applicability lies at the heart of successful deployment and testing strategies.
To sum it up, the imperfections of data variability and model unpredictability need not spell the downfall of predictive aspirations. With methodical application and strategic foresight, cross-validation methods provide an arsenal for designing models’ future pathways. This journey beckons with a promise, and for those willing to embrace its complexity, the rewards of predictive excellence await, wrapped neatly within the methods of model generalization using cross-validation.
Embark on this journey, armed with methodology, buoyed by strategy, and guided by cross-validation wisdom—the ultimate toolkit for turning the ordinary into the extraordinary.