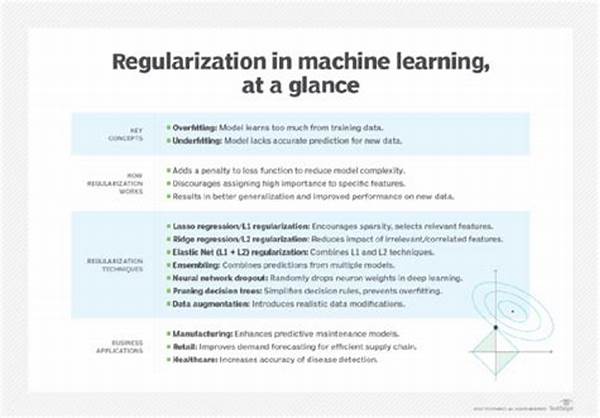
Regularization Methods in Machine Learning
In the ever-evolving universe of machine learning, where data reigns supreme and algorithms are akin to modern-day alchemy, there’s a silent hero that stands guard against the chaotic pitfalls of overfitting—regularization. Picture this: you’ve just built an intricate machine learning model. It’s smart, perhaps too much for its own good, capturing every nuance of your training data to the point where it starts concocting patterns out of noise. Imagine this model taking a standard exam; it’d ace the training questions but struggle with anything unfamiliar. What you need is restraint, a way to balance this model’s zeal for perfection with a pragmatic dash of moderation. Enter regularization methods in machine learning, a suite of techniques designed to refine models, balancing complexity with precision.
Regularization is akin to a reality check for machine learning models, a gentle reminder that perfection is often the enemy of good. By introducing a penalty on the magnitude of model features, regularization methods ensure our models don’t chase after overfitting utopias. But how exactly does this work? L1, L2, Elastic Net—these terms might strike you as cryptic algorithms concocted by tech wizards, yet they come with the promise of transforming how our models interact with data. L1 regularization, adorned with the term Lasso, is like organizing a messy closet, keeping only the essentials. L2, or Ridge, applies more even pressure, like gently tying up multiple cables into a neat bundle. Combining these, Elastic Net captures the best of both worlds. It’s a dance of precision, efficiency, and performance.
What are Regularization Methods?
To delve deeper into the heart of regularization methods in machine learning, let’s consider why they pique the interest of data scientists and machine learning engineers worldwide. At the crux of their appeal is their ability to simplify highly complex models, stripping away unnecessary noise and variability. This simplification results in a model that generalizes better to unseen data, a classic case in point being a neural network. By adding a regularization component to the loss function, we compel the network to minimize both error and the complexity of the model simultaneously, leading to enhanced predictive power. Such is the allure of regularization that numerous real-world success stories continue to emerge, validating its undeniable influence.
—
An In-Depth Exploration of Regularization Methods
The Essence of Regularization
Regularization methods in machine learning aren’t just about pruning excessive complexity; they serve as a quintessential testimony that in the realm of technology, less is often more. As a machine learning enthusiast or a seasoned professional, understanding regularization can transform your approach from crafting clunky, overly sensitive models to pioneers of efficiency and accuracy. Imagine you’re tasked with building a recommendation system. Without regularization, your model, while sophisticated, risks over-interpreting user patterns, ultimately suggesting ill-fitted recommendations. Regularization comes to the rescue, helping your model become intuitive rather than intrusive, setting the stage for remarkable real-world applications.
Types of Regularization: From L1 to Beyond
Peering into the world of regularization methods in machine learning, we encounter an array of techniques each tailored for different scenarios. L1 regularization, known for instilling sparsity, is particularly useful when dealing with datasets burdened by many irrelevant features. Meanwhile, L2 regularization discourages large weights, paving the way for smoother, more stable predictions. Then there’s Elastic Net regularization, the master of synergy, merging L1 and L2’s best aspects to tackle correlated variables proficiently. The versatility of these regularization methods shines through in their adaptability, capable of being tailored to a multitude of machine learning landscapes, from simple linear models to complex neural networks.
—
Discussions on Regularization Methods in Machine Learning
Regularization as a Game-Changer
In the grand arena of machine learning, data-driven decisions are not just valuable but pivotal. Yet, herein lies the challenge: harnessing every bit of information without succumbing to irrelevancies or noise. Regularization emerges as a key component, ensuring that models are battle-ready, primed for real-world applications. This balance of precision and robustness is not an accident but an orchestrated symphony achieved through these deftly wielded techniques.
Take a step into the world of predictive analytics; it’s grandeur contained in simplicity. In industries like finance, healthcare, or even entertainment, regularization methods in machine learning empower models to discern meaningful patterns. They drive decisions that aren’t just informed but transformative, optimizing business strategies, enhancing customer experiences, and even saving lives by accurately predicting outbreaks or market shifts. Regularization, therefore, isn’t mere technical jargon; it is a cornerstone of effective machine learning.
Regularization Methods in Machine Learning: A Path Forward
Reflect on regularization methods in machine learning as trusted guides leading us toward more reliable models. The future promises even more fascinating advancements as regularization techniques evolve in complexity and capability. It’s not just about reducing overfitting anymore; it’s about pioneering transformative changes in how machines learn, adapting to future datasets with unprecedented proficiency. Regularization is not merely an enhancement; it’s a necessity, a journey into the very essence of efficient and scalable machine learning practices.
—
Visual Illustrations of Regularization Methods in Machine Learning
Illustrations as Educational Tools
Utilizing visual aids to explain regularization methods in machine learning can simplify complex concepts into digestible pieces of information. Imagine an infographic that captures these methods’ intricacies while remaining accessible to enthusiasts and experts alike. Visual learners particularly benefit from such educational tools, finding clarity in images where words alone might fall short. A comic strip showcasing a machine learning model humorously ‘choosing’ its best features or a detailed diagram of the Elastic Net’s mechanism—these creative approaches forge deeper understanding, connecting abstract theory with tangible visualization.
In conclusion, regularization methods in machine learning represent a fusion of art and science, a fine-tuned balancing act between simplicity and sophistication. They illuminate the path to revolutionary data-driven insights, offering an invitation to practitioners across domains to embrace their potential and elevate their models to new heights of performance and relevance.