Hey there, fellow data enthusiasts! If you’re delving into the world of machine learning, chances are you’ve stumbled upon the term “cross-validation.” Cross-validation best practices can be a game-changer, allowing you to evaluate how your models will perform on unseen data. In the ever-evolving realm of data science, it’s crucial to know the tricks of the trade, and that’s where cross-validation steps in. Grab a cup of coffee, relax, and let’s dive into the essentials of mastering this technique!
Read Now : Advanced Ai Algorithms For Cybersecurity
The Fundamentals of Cross-Validation
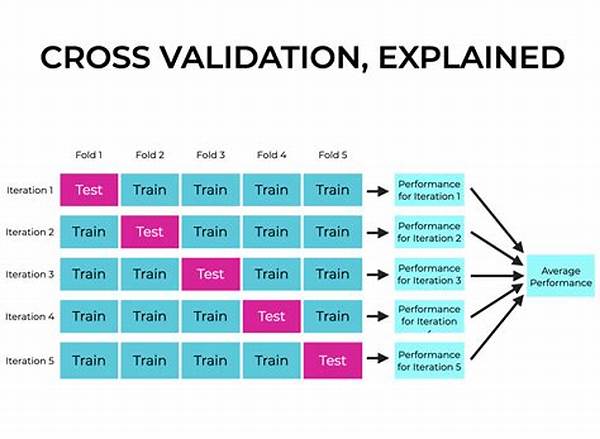
So, what’s the deal with cross-validation, anyway? Essentially, it’s like giving your model a mini workout routine. Instead of training your model on one set of data and hoping for the best, cross-validation helps you split your data into several parts, training your model on some parts and testing it on others. This not only cheers you on in creating more reliable models but also boosts your confidence in its predictions.
What’s awesome about cross-validation best practices is that they act like a safety net, ensuring your model doesn’t just memorize the training data but learns to generalize. There are a variety of techniques out there, from the simple k-fold to the fancy-pants leave-one-out method. Each method comes with its pros and cons, but they all strive for the same goal: making your models robust and ready to face unseen data. Next time you’re designing a machine learning model, remember to give cross-validation the front seat in your analytical toolkit.
Cross-validation is akin to a dress rehearsal for your data models. It tests their performance before the main event, which, in this case, is real-world data prediction. By injecting cross-validation best practices into your learning routine, you ensure that your predictions don’t crash under the pressure of real-world applicability. Trust this ally, and you’ll find yourself building models that are not just theoretically sound but practically stellar. Whether you’re dealing with a dataset that’s a toddler or one that’s a monumental challenge, cross-validation is your reliable companion.
Common Techniques in Cross-Validation
1. K-Fold Cross-Validation: This is the bread and butter of cross-validation best practices. You split your data into ‘k’ subsets, training on ‘k-1’ and testing on one. Repeat this ‘k’ times, and bingo! You’ve got results that scream reliability.
2. Stratified K-Fold: For those who like things equally represented, this one’s for you. It splits the data into ‘k’ folds, preserving the percentage of samples in each class. Cross-validation best practices emphasize this approach when dealing with imbalanced datasets.
3. Leave-One-Out Cross-Validation (LOOCV): If you’re a perfectionist, LOOCV is calling your name. Each instance is a test set once, and the rest becomes the training set. It’s intense but offers a thorough assessment.
4. Time Series Cross-Validation: If your data has a sense of time flow, respect it. Time series cross-validation honors the timeline, ensuring that future predictions aren’t based on past leaks. A must-have in cross-validation best practices for time-ordered data.
5. Monte Carlo Cross-Validation: It shakes things up with randomness. Random subsampling creates training and test data multiple times, giving models a robust performance check. Think of it as a flex exercise among cross-validation best practices.
Benefits of Embracing Cross-Validation
Confidence in model performance cannot be measured by just a single number. It involves understanding the intricacies of variation and stability in outcomes. Cross-validation best practices open a window into this comprehension, showing not just how well a model does but how consistently it can replicate its triumphs. By implementing these practices, you’re not just keeping mishaps at bay; you’re laying bricks on the path to predictive excellence.
The core advantage of cross-validation best practices lies in achieving unbiased estimations. It ensures that the model is not overfitting — or underfitting, for that matter — by testing it thoroughly with multiple data subsets. Balancing is the name of the game. Whether you’re a seasoned data wizard or just dipping your toes into the tech pool, implementation of cross-validation into your routine can create ripples of enhanced effectiveness in your analysis efforts.
Essential Steps to Implement Cross-Validation
Understanding the nuances of cross-validation is cool, but isn’t it fun to roll up your sleeves and jump into action? Start by dividing your data wisely. Following cross-validation best practices involves understanding the specific needs of your dataset. Don’t just pick any method randomly; think about what suits your data challenges.
Remember to shuffle your data to ensure randomness. Picking subsets haphazardly can lead to biased outcomes. Cross-validation best practices remind you that being systematic brings out the pristine essence of data performance. Finally, cross your fingers and compute the results across folds. Patience pays off, and you’ll find those performance metrics singing a harmonious tune.
Tips for Optimizing Cross-Validation
Knowing the tricks of the trade can forever be a game-changer. So, let’s optimize those efforts:
1. Balance Your Folds: Each fold should represent the whole as much as possible.
2. Guard Against Leakage: Ensure training data never spills into testing sets.
Read Now : Proactive Threat Prevention Strategies
3. Adapt to Data Size: Lesser known fact: bigger isn’t always better. Pick ‘k’ that suits your data volume.
4. Harness Resources Wisely: Cross-validation can be computation-heavy. Use efficient methods.
5. Keep Learning: Stay updated with evolving cross-validation best practices.
6. Analysis of Variance: Take note of variability in results across folds to address potential issues.
7. Review Bias and Variance Tradeoff: Keep the interplay between bias and variance in check.
8. Interlace Cross-Validation with Hyperparameter Tuning: Use cross-validation while adjusting hyperparameters.
9. Testing Diverse Models: Test multiple models to determine cross-validation metrics for various techniques.
10. Evaluation of Real-World Scenarios: Align cross-validation with real-world data to verify effectiveness.
Maximizing Results with Cross-Validation
Whether you’re playing around with predictive models or solving industrial-scale data problems, embedding cross-validation best practices into your workflow cannot be emphasized enough. A simple misstep in model validation can lead to shaky conclusions. Fine-tuning your approach and ensuring consistency in results builds robust models that withstand the test of time and complexity.
While embracing cross-validation best practices, visualize your goals and datasets gradually. Balancing intricacy with efficiency can be your guiding light. The possibilities for refining and making the models adaptable to various challenges multiply. There’s wisdom in patience, for slow and steady wins this tech-savvy race as well.
Parting Thoughts on Cross-Validation
It’s been a whirlwind tour traversing the landscape of cross-validation best practices. Whether you’re a seasoned expert or an enthusiastic beginner, these practices are indispensable. Anchoring your machine learning models on these fundamentals ensures you reach unparalleled heights in prediction accuracy and reliability.
Keep the spirit of curiosity rejuvenated and alive. With cross-validation by your side, conquering data puzzles becomes a thrilling adventure, not just a task. Push those analytical boundaries and transform your findings into patterns of accuracy. Remember, every innovative model is a step forward toward unprecedented predictions. Cheers to the endless potential of data exploration!