Optimizing Prediction Models with Cross-Validation
In the dynamic world of data science and machine learning, the need to enhance the accuracy and reliability of prediction models is more crucial than ever. Imagine crafting a masterpiece only to find it’s riddled with flaws— that’s what happens if prediction models aren’t meticulously optimized. Enter cross-validation, the unsung hero in the data scientist’s toolkit, which provides a rigorous framework to test and tune models, ensuring they perform at their best when they’re needed most. In a field saturated with data and demanding precision, cross-validation acts as the barometer of a model’s true capability, allowing developers to transform raw algorithms into insightful predictive tools.
Cross-validation is akin to taking your prediction model out into the wild to see how it truly fares against different conditions. By partitioning data into subsets, the model is trained and evaluated multiple times, each with distinct segments, providing a comprehensive assessment of its performance. This technique allows for discerning model weaknesses, mitigating overfitting risks, and ensuring that when predictions are made, they’re not just shots in the dark but rather well-informed assertions. For data enthusiasts and professionals alike, mastering the art of optimizing prediction models with cross-validation is a journey toward achieving the highest standards in predictive analytics.
The Science of Reproducibility
Cross-validation offers the allure of reproducibility, a scientific cornerstone. In a world where every decision leans on data-derived insights, ensuring that those insights are consistently accurate across different datasets is paramount. This process eliminates the biases that can taint a model when evaluated solely on one set, ensuring robust performance that users can rely upon.
Why Cross-Validation Matters
Incorporating cross-validation into model development is not only a nod to methodological rigor but also a strategic advantage in a competitive data landscape. Models that can withstand the scrutiny of cross-validation are those that instill confidence, earn stakeholder trust, and ultimately drive better decision-making. Embracing this practice is, therefore, not just a technical choice but a business imperative.
Enhancing Model Accuracy with Cross-Validation
The quest to enhance prediction models doesn’t stop at baselines. Precision is the name of the game. Predictive analytics demand fidelity, and optimizing prediction models with cross-validation ensures models aren’t just created for the sake of it but are refined continuously to adapt, learn, and excel.
How It Works
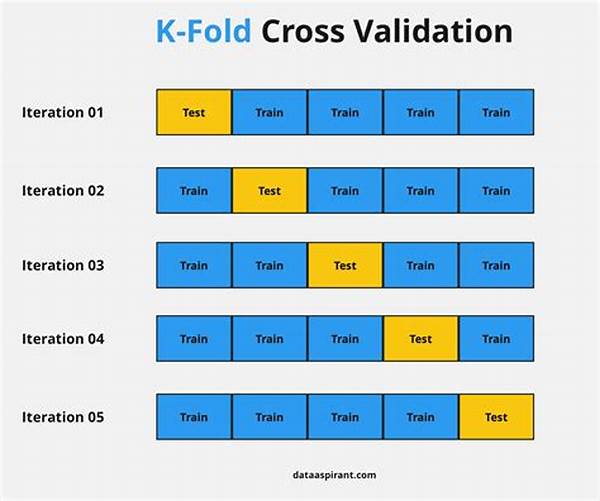
Cross-validation divides data into subsets, cycling through each as a test set while the others are used for training. This cyclical process, therefore, provides repeated opportunities to hone a model’s accuracy and identify potential overfitting or underfitting. The result? A model that’s not just a paper tiger but a true titan in the field.
Practical Applications
From predicting consumer behavior to health diagnostics, the applications are as endless as they are vital. When optimizing prediction models with cross-validation, you set a precedent for quality, functionality, and reliability. This process resonates beyond the algorithms into meaningful, actionable insights that transform sectors and industries.
Here are some crucial details about optimizing prediction models with cross-validation:
Building Robust Models with Cross-Validation
Understanding the process begins with grasping the scale of benefits provided by optimizing prediction models with cross-validation. Think of it as the move that changes the game, allowing analysts to benchmark their models with confidence.
Unpacking the Benefits
Employing cross-validation isn’t merely beneficial—it’s transformative. It bridges the gap between theoretical models and their real-world applications, ensuring predictive accuracy. Models become scalable, adaptive, and more importantly, validated for unseen data, which is a triumph in predictive analysis.
Real-World Success
Among data scientists, employing cross-validation is more than a best practice; it’s a rite of passage. Stories abound of teams identifying flaws early, adjusting model parameters effectively, and ultimately launching successful predictive campaigns—thanks to cross-validation.
By focusing on optimizing prediction models with cross-validation, we enter a new realm of predictive analytics where reliability, scalability, and innovation go hand in hand.
Key Considerations for Implementation
By harnessing the full potential of cross-validation, prediction models transform from good to great, setting new standards for what is achievable in the realm of data science.