Cross-Validation Methods for Model Accuracy
In the realm of machine learning, building a model that not only fits well with the training data but also generalizes effectively to unseen data is paramount. Imagine whipping up a batch of scrumptious cookies; they might taste fabulous when fresh out of the oven, but the true test is when you serve them to your friends the next day! In much the same way, a model might appear flawless when evaluated on its training data, but how do we ensure its performance is equally stellar on new data? Enter cross-validation methods for model accuracy. These are techniques designed to give us a sneak peek into the future performance of our models, without the hassle of collecting entirely new data sets every time we make a tweak.
Now, the cross-validation methods for model accuracy work like a set of honesty testers for your model. Picture a reality TV show where contestants are tested in various situations to reveal their strengths and weaknesses. Just as viewers enjoy the drama of seeing how each participant tackles diverse challenges, in machine learning, we relish observing a model thrive or falter across different sub-datasets. Cross-validation doesn’t just test the model once; it runs it through the wringer multiple times—each with a different slice of data as its proving ground. But, why all this ado about cross-validation methods for model accuracy? The fascinating part lies in the way these methods lend a more complete and reliable evaluation of the model’s capabilities, much like having multiple judges rate a performance rather than relying on a single opinion.
From a marketing perspective, employing cross-validation not only enhances your model’s credibility but also boosts your confidence in its predictions. Think of it as the rigorous product testing phase in product marketing. Without it, you risk rolling out a delightful-but-defective gadget into the world. Cross-validation methods like k-fold, leave-one-out, and stratified sampling, act as invaluable pre-launch tests. They simulate how the model will perform in the wild, with varied data and scenarios, akin to conducting a product launch dry-run. With this hands-on testing, stakeholders can rest easy knowing their investment is secure and audiences can trust the quality of predictions offered by the model. So, investing in robust cross-validation methods is essentially equipping your model with a sturdy warranty card—it’s a promise of performance.
Popularity of Cross-Validation in Modern Data Science
In conclusion, cross-validation methods for model accuracy are not merely optional tools; they are essential utilities for any serious data science practitioner. Their role in predicting future success cannot be overstated, much like a good rehearsal ensures a standing ovation. By systematically partitioning data and evaluating performance across these splits, cross-validation methods furnish a well-rounded picture of model accuracy. They’re the unsung heroes, toiling backstage, ensuring each model is stage-ready for the big prediction performance.
Exploring Different Cross-Validation Techniques
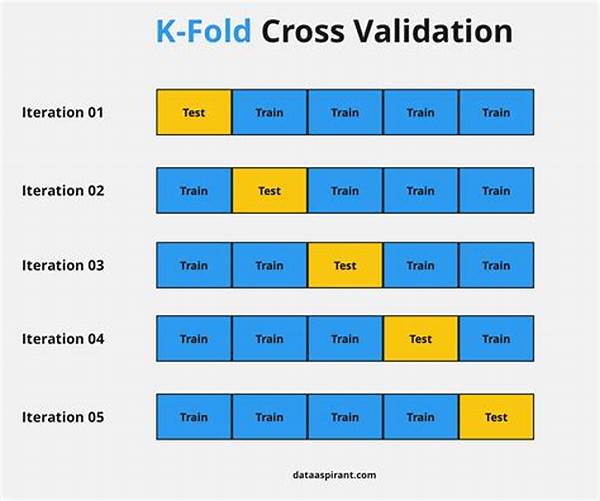
Cross-validation methods for model accuracy play a pivotal role in the landscape of data science and machine learning. Each technique brings its own flavor to the mix, much like choosing between gelato and sorbet, or deciding on a spicy curry over a mild dal. The choice depends on the flavor profile, or in this case, the pattern and volume of data at hand. There’s the quintessential k-fold cross-validation, where data gets divided into ‘k’ number of groups, with each group taking turns as the testing set while the rest form the training set. This rotation demystifies any one-off bias by ensuring that every slice of data gets its turn in the spotlight. It’s like rotating tasks among a team to balance skills and ensure robust coverage.
Leave-one-out cross-validation is akin to going solo in a group dynamics assignment; every single observation gets its moment as the test set while the remainder serve as the training ground. Though computationally expensive, it’s the most meticulous in ensuring nothing gets left out. On the other hand, stratified cross-validation gives equal representation to different classes within the data, much like ensuring that every genre features in a music festival playlist. This approach prevents skewness, helping maintain the harmony of the model’s performance across different data facets.
Within modern business analytics and research, these methods are revered as essential checkpoints — akin to a race car making pit stops to ensure optimal performance. As analysts and data scientists harness these techniques, the outcomes are not merely predictions; they are informed insights powered by proven accuracy. Indeed, investing time in mastering cross-validation methods could very well be the best return on investment a budding data wizard can make.
Understanding the Layers of Model Testing
A thorough understanding of cross-validation methods for model accuracy calls for a deep dive into each layer of model testing. Take k-fold cross-validation, for instance, an approach that divides the dataset into ‘k’ exclusive folds, providing a more comprehensive assessment of model performance. On the flip side, you have leave-one-out cross-validation, offering the granularity of evaluating model efficacy on single data points against the collective rest.
Stratified cross-validation, however, emphasizes maintaining consistent distributions across folds, mirroring the class representation in the whole dataset. This is key in classification tasks where minority classes might otherwise be overlooked. It’s a bit like ensuring every key in a piano gets played—no notes left untouched, no biases left unchecked. Finally, there’s the time series split—ideal for data with a time component. This method incrementally adds data to the training set while moving through the timeline—an exquisite dance with the time dimension.
While each method has its strengths and drawbacks, choosing the right one aligns with understanding your data’s nature and the model’s purpose. For students and professionals navigating through machine learning, appreciating these subtle differences can turn an ordinary report into a compelling narrative with insights grounded in statistically sound evaluations. Ultimately, cross-validation stands as a testament to our commitment to accuracy, evidencing our pursuit of translating complexity into clarity through informed decision-making.
Benefits of Cross-Validation Methods
Choosing the Right Cross-Validation Method
When choosing a cross-validation method, several factors play a critical role. The characteristics of the dataset, such as size and distribution, are paramount. For smaller datasets, leave-one-out cross-validation offers a high granularity approach, but beware of its computational complexity. On the other end of the spectrum, k-fold cross-validation offers a balanced trade-off between thoroughness and computational load. An understanding of these nuanced differences will ensure data science enthusiasts and professionals alike select the ideal technique for their specific needs.
Ultimately, cross-validation should be perceived as both a shield and a sword. It protects the integrity of the model by mitigating biases, and simultaneously, it empowers practitioners to wield predictions with confidence. This dual nature makes cross-validation indispensable within the evolving field of data analytics—fueling not only predictive accuracy but also advancing our quest for insightful decision-making.
Delving Into Cross-Validation Technique Variations
Cross-validation methods are not merely limited to the classics. Variations arise to handle specific data intricacies, offering tailored approaches for unique challenges like time dependencies or highly imbalanced datasets. For instance, time series cross-validation handles the temporal dynamics by training on past data and validating on the future, while stratified k-fold ensures class distributions are maintained across splits, crucial for classification problems with skewed classes.
As the field continues to evolve, cross-validation variations will emerge to meet new data challenges, ensuring that every model is battle-tested before deployment. Enthusiasts, stakeholders, and industry veterans alike, watch closely as these developments unfold—the ongoing saga of refining predictive excellence.
Top 10 Tips for Implementing Cross-Validation
1. Understand Your Data: Know the size, nature, and class distribution of your dataset before selecting a cross-validation method.
2. Choose the Right Technique: Evaluate the data characteristics and computational resources to select an appropriate method.
3. Balance Complexity with Performance: Opt for the complexity your resources can handle without compromising output.
4. Address Overfitting: Use cross-validation regularly to ensure your model’s performance doesn’t hinge on one specific dataset.
5. Evaluate Multiple Models: Compare different algorithm outputs for the best results.
6. Hyperparameter Tuning: Utilize cross-validation for optimizing model settings effectively.
7. Time Series Data Caution: For time-dependent data, ensure splits respect temporal order.
8. Stratification for Imbalance: Look for stratified variations where class imbalance is prominent.
9. Combine Methods Creatively: Sometimes, a blend of techniques yields the best results.
10. Evaluate Iteratively: Continuously use cross-validation throughout development, not just at the end.
Ultimately, implementing cross-validation is indispensable in translating raw data into insights that achieve accuracy and reliability. It’s not just a step in a process; it’s an art and science pivotal to model building in our data-driven world. Cross-validation forms the bedrock of advanced analytics, ready to elevate data science endeavors to unprecedented heights.