In the ever-evolving world of data science and machine learning, ensuring the robustness and reliability of your models is quintessential. Enter k-fold cross-validation—a must-have tool in your machine learning toolkit. If you’re venturing into model validation, it’s crucial to grasp the best practices for k-fold cross-validation, which serve as a benchmark to test the viability and resilience of your models. Imagine you’re a data warrior wagging your digital sword against overfitting, punctuated by the daunting adversary of data leakage! Yes, it’s quite the journey. Bridging statistical prowess with technical acumen is the order of the day.
Read Now : Overfitting And Underfitting Issues
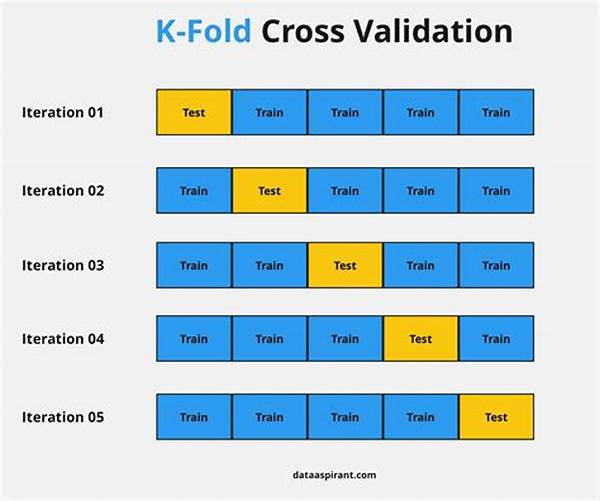
Understanding k-fold cross-validation gives you the satisfaction similar to deciphering a complex enigma, providing a secure pathway to attain generalization accuracy in real-world scenarios. It divides your dataset into k subsets (or “folds”). You’ll train your model k times, each time with a different fold set aside for testing. The elegance of this system lies in its simplicity and effectiveness, offering an exhaustive way to leverage small or limited datasets. But, like any superpower, it needs careful handling—this is where best practices come into play.
Priming Your Cross-Validation Model for Prime Time
Navigating through k-fold cross-validation involves a ceremonial dance of data fidelity and integrity. Ensuring uniformity in data distribution across folds and being meticulous about preprocessing steps are gospel here. Also, one can’t overstate the importance of choosing an optimal value for k: too small, and you risk high variance, too large, and the computational burden augments. When implemented proficiently, these best practices for k-fold cross-validation guide you gracefully through the maze of data validation.
When the allure of seamless machine learning models beckons, adhering to these prime strategies illuminates the path to precision. Suitable distribution, apt preprocessing integration, and pragmatic fold numbers form the trifecta of a formidable k-fold validation strategy. Equipped with these insights, you’re ready to transcend the plains of basic model training toward unparalleled model refinement.
Ensuring Robust Models: Best Practices Overview
Understanding the Foundational Need
Considering how pivotal model validation is, devising a foolproof validation strategy can’t be underestimated. The best practices for k-fold cross-validation encompass everything from data preprocessing to ensuring equal distribution. Careful and consistent adherence to these practices lays the groundwork for attaining credible, replicable results. Researchers worldwide have underscored ensuring data uniformity and selecting appropriate k values, drawing from robust case studies and extensive experimentation. Emulating these brings a distinct certainty to your validation process.
Navigating Common Validation Hurdles
In practice, the real-world application of these strategies often presents intriguing challenges. Identifying and rectifying data leakage or implementing stratified folds when embracing cross-validation ensures the validity of the results. Often, anecdotal wisdom derives from experienced data scientists who’ve traversed these pathways. Engaging with the community and sharing insights can exponentially enhance understanding and application of best practices for k-fold cross-validation. In essence, learning from shared experiences makes this intricate journey both enjoyable and effective.
Unveiling Actionable Steps for Better Cross-Validation
Delving into the Validation Process
Exploring the Need for Consistency
Read Now : Bidirectional Lstm For Pos Tagging
In achieving reliable models, the impetus on maintaining data integrity cannot be overstated. The best practices for k-fold cross-validation emphasize consistent data handling, providing uniform analysis across folds. Statistical evidence from various research initiatives underscores the significance of stratified sampling in maintaining equilibrium between class proportions. While encountering inconsistent class distributions might tempt one to improvise, following a methodical strategy ensures credible and generalizable outcomes.
Building Trust through Shared Experiences
The pathway to mastering cross-validation unfolds optimally when augmented by collective wisdom. Engaging in community-driven platforms and conferences serves as a catalyst to refine your approach. For instance, virtual seminars and workshops spotlight crucial techniques, delving into nuances, unraveling key analytical revelations. Moreover, testimonials from seasoned practitioners can illuminate common pitfalls, create learning opportunities, and enhance understanding of best practices for k-fold cross-validation.
Visual Representations and Depictions
In engaging with the expansive array of visuals, practitioners can better comprehend and execute effective cross-validation strategies. Visual aids foster a deeper intuitive grasp of the diverse facets within best practices for k-fold cross-validation, rendering your validation initiatives efficient, effective, and enlightening. These illustrative tools can serve as a profound educational medium, driving complex concepts into tangible understanding, contributing vividly to enhanced data modeling efficacy.
—
By following structured and methodically curated insights, features, and expert opinions, embracing the excellence of k-fold cross-validation becomes not only an educational journey but a practical adventure in data reliability. As we traverse this complex terrain, leveraging communal expertise and historical comprehension becomes imperative in effectively implementing best practices for k-fold cross-validation.